
开源AI工具:快速终端原生应用(TUI)和CLI
AI Skill Hub 推荐使用:开源AI工具:快速终端原生应用(TUI)和CLI 是一款优质的AI工具。AI 综合评分 7.5 分,在同类工具中表现稳健。如果你正在寻找可靠的AI工具解决方案,这是一个值得深入了解的选择。
📚 深度解析
**为什么要使用开源工具而非商业 SaaS?**
对于个人开发者和有隐私需求的用户,本地部署的开源工具意味着数据不离本机,不受第三方服务商的数据政策约束。同时,开源工具通常没有使用次数限制和月度费用,一次安装即可长期使用,对于高频使用场景的总拥有成本(TCO)远低于订阅制商业工具。
**安装与环境准备**
开源AI工具:快速终端原生应用(TUI)和CLI 依赖 Rust 运行环境。建议通过 pyenv(Python)或 nvm(Node.js)管理 Rust 版本,避免全局环境污染。对于新手用户,推荐先创建虚拟环境(python -m venv venv && source venv/bin/activate),再安装依赖,这样即使出现问题也可以随时删除虚拟环境重新开始,不影响系统稳定性。
**社区与维护**
GitHub Issue 和 Discussion 是获取帮助的最快渠道。在提问前建议先检查 Closed Issues(已关闭的问题),大多数常见问题都已有解答。遇到 Bug 时,提供 pip list 的输出、完整错误堆栈和最小可复现示例,能显著提高开发者响应速度。AI Skill Hub 将持续追踪 开源AI工具:快速终端原生应用(TUI)和CLI 的版本更新,及时通知重要功能变化。
📋 工具概览
快速终端原生应用(TUI)和CLI,支持LLM启动,提供init向导
开源AI工具:快速终端原生应用(TUI)和CLI 是一款基于 Rust 开发的开源工具,专注于 installable、ai、gguf 等核心功能。作为 GitHub 开源项目,它拥有活跃的社区支持和持续的版本迭代,代码完全透明可审计,支持本地部署以保护数据隐私。无论是个人使用还是集成到企业工作流,都能提供稳定可靠的解决方案。
📖 中文文档
快速终端原生应用(TUI)和CLI,支持LLM启动,提供init向导
开源AI工具:快速终端原生应用(TUI)和CLI 是一款基于 Rust 开发的开源工具,专注于 installable、ai、gguf 等核心功能。作为 GitHub 开源项目,它拥有活跃的社区支持和持续的版本迭代,代码完全透明可审计,支持本地部署以保护数据隐私。无论是个人使用还是集成到企业工作流,都能提供稳定可靠的解决方案。
- 开源免费,支持本地部署,数据完全自主可控
- 活跃的 GitHub 开源社区,持续迭代更新
- 提供详细文档和使用示例,新手友好
- 支持自定义配置,灵活适配不同使用环境
- 可作为基础组件集成进现有技术栈或进行二次开发
- 本地部署运行,保护数据隐私,满足合规要求
- 自定义集成到现有系统,扩展技术栈能力
- 作为开源基础组件进行商业化二次开发
# 方式一:cargo install(推荐) cargo install llamastash # 方式二:从源码编译 git clone https://github.com/llamastash/llamastash cd llamastash cargo build --release # 二进制在 ./target/release/llamastash
- 访问 GitHub 仓库页面
- 按照 README 文档完成依赖安装
- 根据系统环境完成初始化配置
- 参考官方示例或文档开始使用
- 遇到问题可在 GitHub Issues 中查找解答
# 查看帮助 llamastash --help # 基本运行 llamastash [options] <input> # 详细使用说明请查阅文档 # https://github.com/llamastash/llamastash
# llamastash 配置说明 # 查看配置选项 llamastash --config-example > config.yml # 常见配置项 # output_dir: ./output # log_level: info # workers: 4 # 环境变量(覆盖配置文件) export LLAMASTASH_CONFIG="/path/to/config.yml"
LlamaStash
![]()
![]()




![]()

![]()

![]()
Zero-overhead, terminal-native llama.cpp launcher.
A fast TUI and CLI with init wizard for launching local LLMs via llama.cpp. One Rust binary that's a TUI, a CLI, a daemon, and an OpenAI-compatible proxy. Zero overhead vs raw llama-server. See benchmarks.
Features
Full detail per feature in FEATURES.md — including trade-offs, contracts, and links into docs/usage.md.
[Zero-to-chat in one command](FEATURES.md#zero-to-chat-in-one-command)
llamastash init— first-run wizard that detects hardware, installsllama-server, picks + downloads a starter GGUF, writes a tuned config, and smoke-launches.- Hardware-aware model recommender with a VRAM-fit filter + composite ranking over a CI-refreshed benchmark snapshot.
llamastash doctor— typed, agent-branchable findings; always exits0.
[Discovers what you already have](FEATURES.md#discovers-what-you-already-have)
- Auto-scans HuggingFace, Ollama, and LM Studio caches, plus user paths.
- Rich GGUF intelligence — architecture, params, quant, native context, chat template, KV-cache-aware memory estimates.
- Smart deduplication — symlinks collapsed, split GGUFs unified, Ollama blobs named.
- Live filesystem watching — new GGUFs appear without a restart.
[Launches anything, supervises everything](FEATURES.md#launches-anything-supervises-everything)
- Daemon-on-demand — one binary as TUI + CLI + daemon; running models survive TUI close.
- Multi-model concurrency — per-model port from a configurable range,
/health-probed state machine. - GPU-aware built-in arch defaults — sensible flags per
(architecture, gpu_backend)with zero YAML. - Intelligent context auto-fit — when
ctxis unset, llamastash picks the largest context that fits free VRAM (or RAM, CPU-only) from the GGUF attention geometry. Sidesteps llama.cpp--fit's 4096 collapse on Linux 7+ iGPUs (AMD Strix Halo) where unified-memory free space is mis-reported. - Typed launch-knob editor with
(source)chips and a layered preset → last-params → arch-defaults → built-ins resolver. - Named presets, favorites, last-params recall.
[A TUI that doesn't get in your way](FEATURES.md#a-tui-that-doesnt-get-in-your-way)
- Keyboard-driven everywhere — vim-style
hjkl+Ctrl+F/Ctrl+Bpaging,0/$top/bottom,gt/gTtab cycling;/filter,u/c/pyank,?help. - Right pane is your smoke test — Logs / Chat / Embed / Rerank over the same OpenAI-compatible endpoints external clients use.
- In-TUI HuggingFace browser — search, sort, paginate, per-file hardware fit, download strip with cancel.
- Theming and rebinding — five themes + custom palette; every action rebindable.
- Accessible by default — dual-encoded status (color + glyph), readable on mono terminals.
- Adaptive layout — works from 60 cells up — below 100 cells the right pane goes drill-in-only; list columns and hint chips drop by priority rank as the pane shrinks so the model name stays readable.
[Drop-in OpenAI + Ollama proxy](FEATURES.md#drop-in-openai--ollama-proxy)
- OpenAI-compatible endpoint at
http://127.0.0.1:11435/v1by default (or the next free port up to11440) — drives every discovered model through one URL; OpenCode, Pi (pi.dev), Cline, llm-cli, the OpenAI SDKs all work as-is. Auto-starts the requested model; falls back to a Ready peer with audit headers (x-llamastash-served-by,x-llamastash-fallback-reason) when launch fails. The default port is11435(one above Ollama's well-known11434) so a llamastash daemon and an Ollama install can co-exist without a port collision. - Ollama discovery surface —
GET /api/tags//api/version//api/ps,POST /api/showso tools that auto-detect Ollama viaOLLAMA_HOSTrecognise llamastash and fall through to the OpenAI-compat endpoints for inference. - Ollama drop-in mode is opt-in. Enable with
--ollama-compat(orproxy.ollama_compat: true/LLAMASTASH_OLLAMA_COMPAT=1) and the proxy claims port11434, answersGET /with the byte-exact"Ollama is running"handshake string, and works as a transparent replacement for the officialollamaCLI and other Ollama-Go-based clients. Leaving compat off keeps the safe coexistence default (port11435,"LlamaStash is running"identity). - Loopback-only, no authentication — single-user local threat model; the proxy refuses LAN binds.
[Built to be safe to run](FEATURES.md#built-to-be-safe-to-run)
- Bearer-token loopback control plane (
runtime.json0600) — the per-daemon token + URL live in$XDG_STATE_HOME/llamastash/runtime.json; same-UID trust, no network exposure. - Hardened fetch substrate — HTTPS-only, host allowlist, redirect/body-size caps, IP-literal refusal.
- Archive-bomb defenses on installers — entry/size/ratio caps; SHA-256 verified before extract.
- Atomic, mode-checked config + state writes —
0600final mode; corrupt state quarantined, not fatal. - Side-by-side daemons — isolated instances via
LLAMASTASH_*_DIR(state / config / cache); each daemon publishes its ownruntime.json.
Note: This is beta software. Rough edges are to be expected. Windows and macOS support is not as well-tested as Linux; Same goes for non-AMD GPUs. Please report issues if you hit them. The llama-server builds are unmodified upstream binaries; any bugs in them are out of scope for LlamaStash.
Install
Pick whichever channel you prefer — all install the same binary. Full per-platform notes, troubleshooting, and the agent-friendly non-interactive path live in INSTALL.md.
```bash
AMD APU - Linux (Ryzen AI Max+ 395 / Radeon 8060S 128GB unified, system ROCm 7.2.3, llama.cpp build `b9440 (e6123e208)`)
chat_turn normalized mode, decode tok/s / TTFT ms. One bench JSON per row (no averaging).
| Tool | small (E2B Q4) | mid (31B Q4) | large_dense (27B Q8) | large_moe (35B-A3B Q8) | Engine notes |
|---|---|---|---|---|---|
| **LlamaStash** | **82.1 / 51** | **9.9 / 468** | **7.5 / 406** | **42.3 / 178** | local HIP/ROCm |
raw llama-server | 81.0 / 51 | 9.9 / 466 | 7.5 / 406 | 43.1 / 185 | local HIP/ROCm |
| LM Studio 2.18.0 | 91.1 / 187 | — (crash¹) | — (crash¹) | — (crash¹) | bundled ROCm 6.4 vendor (see footnote) |
| Ollama 0.24.0 | 50.8 / 224 | 4.8 / 1096 | 2.6 / 1750 | 12.2 / 484 | bundled |
¹ LM Studio's bundled ROCm vendor libraries (v6.4) abort in ggml_cuda_error during backend init on gfx1151 (Strix Halo) across all LMS-shipped runtimes. System ROCm 7.2.3 loads the same models cleanly via raw llama-server, so this is an LMS vendor-bundle limitation. LMS Vulkan numbers are in the benchmark blog and in the final report.
AMD APU — Vulkan addendum (LlamaStash vs LM Studio, 2026-06-01)
| Tool | small (E2B Q4) | mid (31B Q4) | large_dense (27B Q8) | large_moe (35B-A3B Q8) |
|---|---|---|---|---|
| **LlamaStash** | **101.2 / 55** | **10.8 / 671** | 7.5 / 196 | **50.7 / 72** |
| LM Studio 2.18.0 | 93.6 / 191 | 7.1 / 2307 | **8.0 / 801** | 38.4 / 227 |
Same backend (Vulkan b9440 / vulkan-avx2@2.18.0), same GGUF bytes. raw llama-server and Ollama omitted: the wrapper-overhead claim already covered by the HIP table; Ollama mainline has no Vulkan support.
NVIDIA - Linux (RTX 3050 Ti, 4 GiB VRAM, llama.cpp build `b9360`)
| Tool | CUDA (gemma-3-4b Q3 defaults) | Vulkan (gemma-3-4b Q3 defaults) |
|---|---|---|
| **LlamaStash** | **41.1 / 74** ✦ | **42.0 / 113** |
raw llama-server | 36.6 / 110 | 37.5 / 148 |
| LM Studio 2.16.0 | **48.7 / 318** | **48.3 / 308** |
| Ollama 0.24.0 | 40.7 / 120 | 42.0 / 115 |
✦ LlamaStash leads raw llama-server in defaults mode (12–16% decode, 33–49% TTFT) via the hardware-aware defaults overlay; normalized mode: within ≤0.5 tok/s. Vulkan decode ≥ CUDA on this hardware in 26 of 28 cells (median +5%). Curated report with six findings: linux-nvidia-final.md.
Apple M1 - macOS (16 GB unified memory, Metal, llama.cpp build `9330 (328874d05)`)
| Tool | small (Qwen2.5-0.5B Q4) |
|---|---|
| **LlamaStash** | **95.6 / 18** ✦ |
raw llama-server | 91.9 / 20 |
| LM Studio | 88.4 / 68 |
| Ollama 0.24.0 | 79.6 / 102 |
✦ LlamaStash leads raw llama-server on M1 in defaults mode (99.0 vs 92.3 tok/s, 15 vs 19 ms TTFT) because its Metal defaults overlay injects hardware-optimal knobs at startup. Normalized mode: 92.2 vs 91.5 — within 1%. Curated report: macos-m1-final-report.md.
Quickstart
```bash
AI Usage
Multiple AI Coding Harnesses and LLMs were heavily used to create this project.
Screenshots
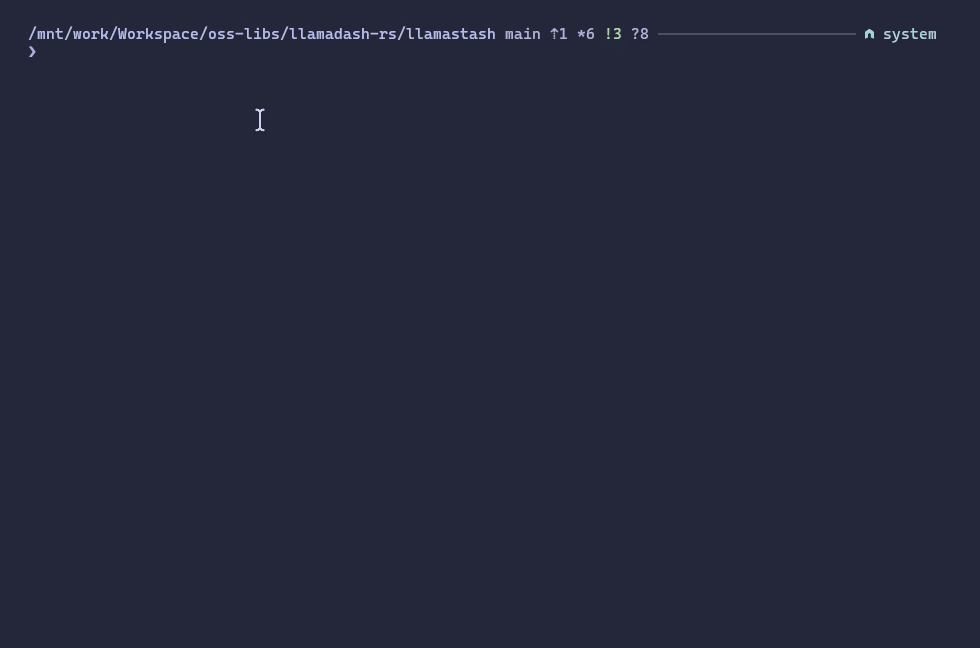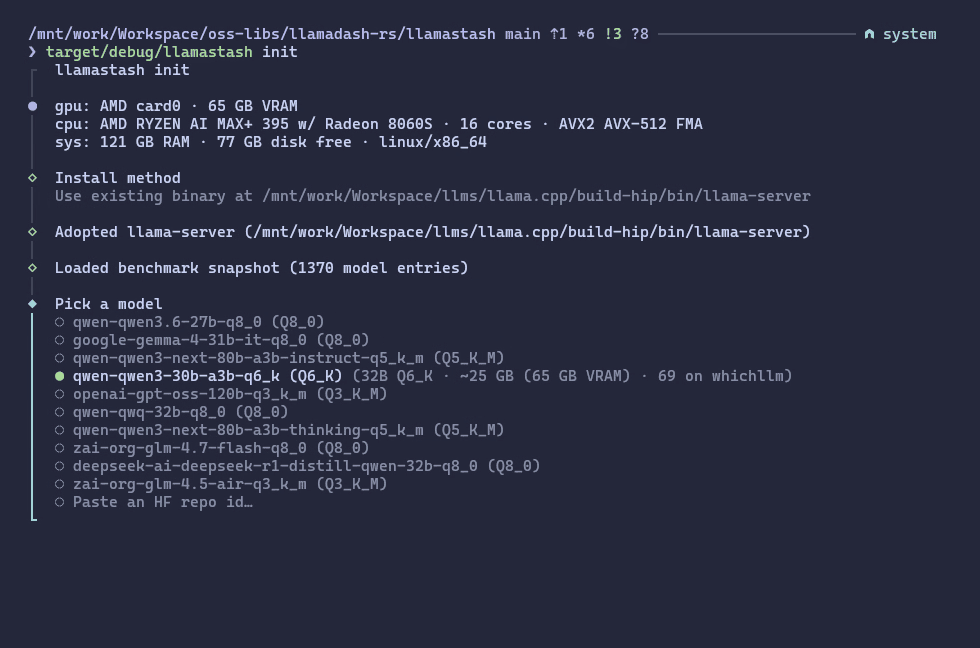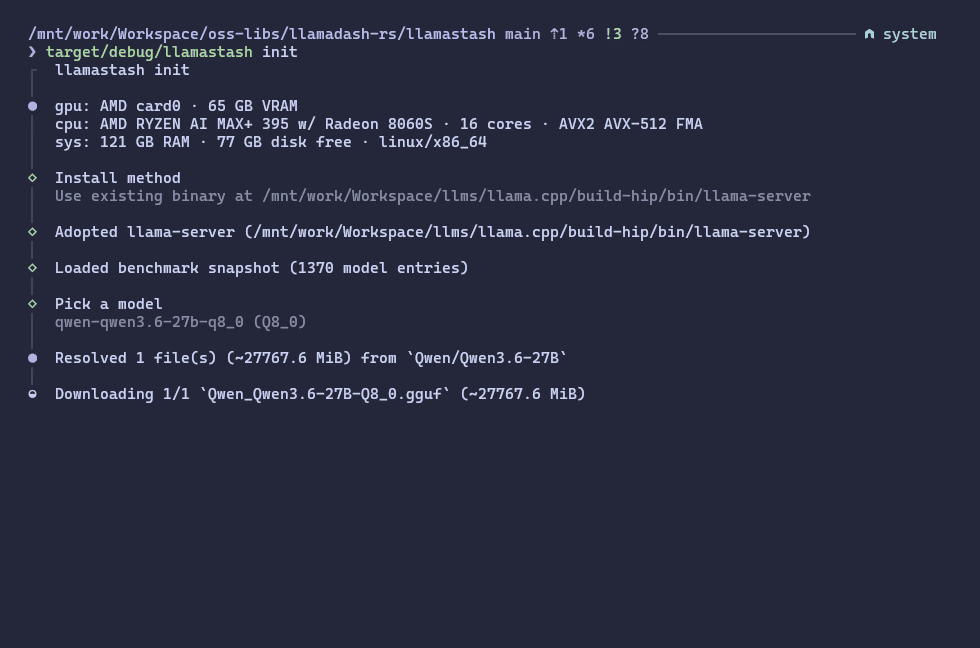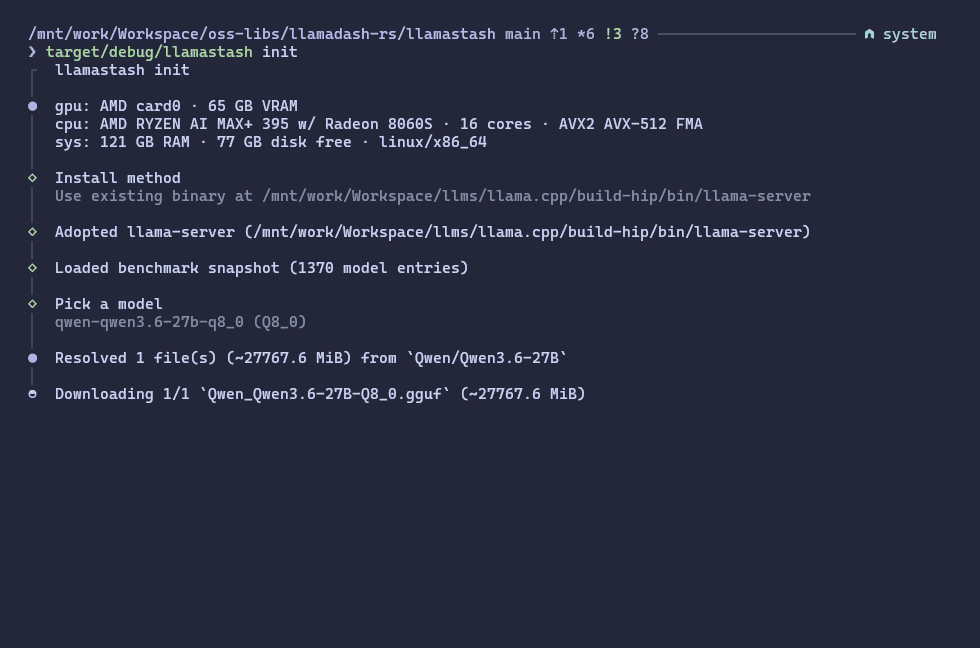
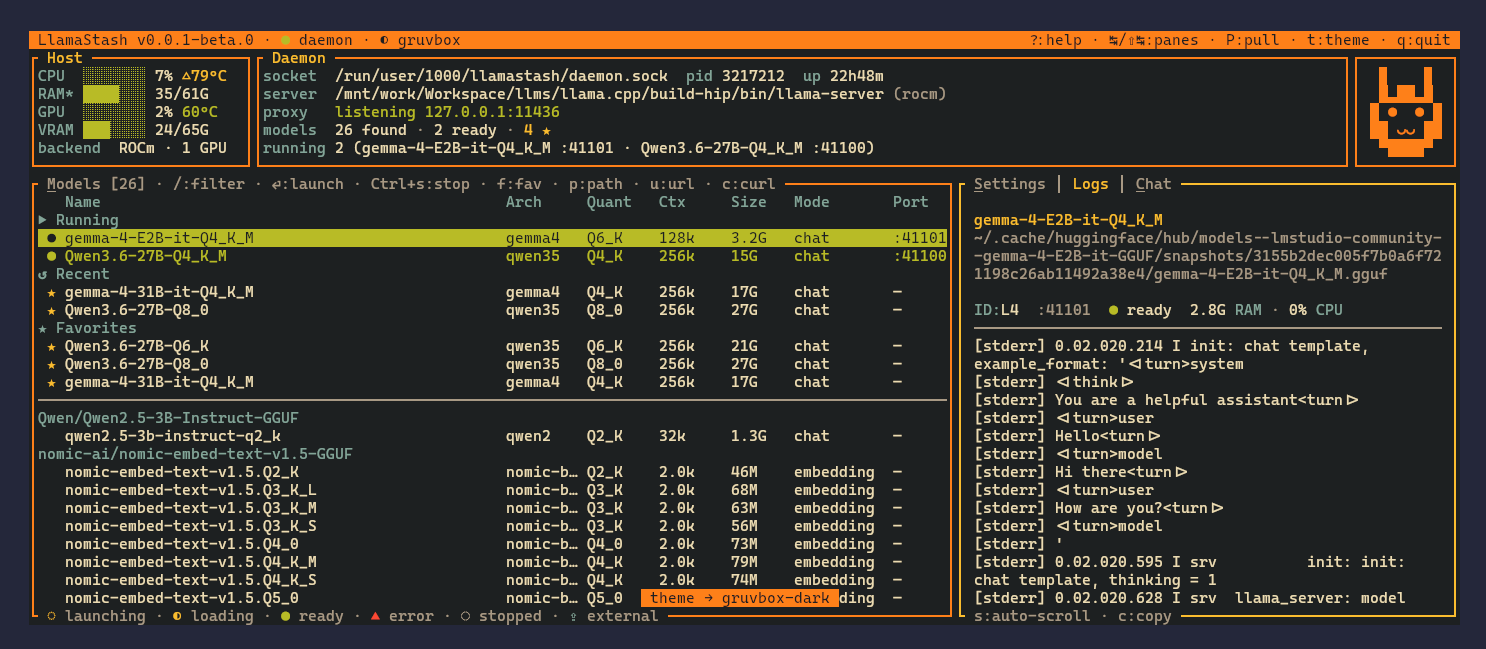
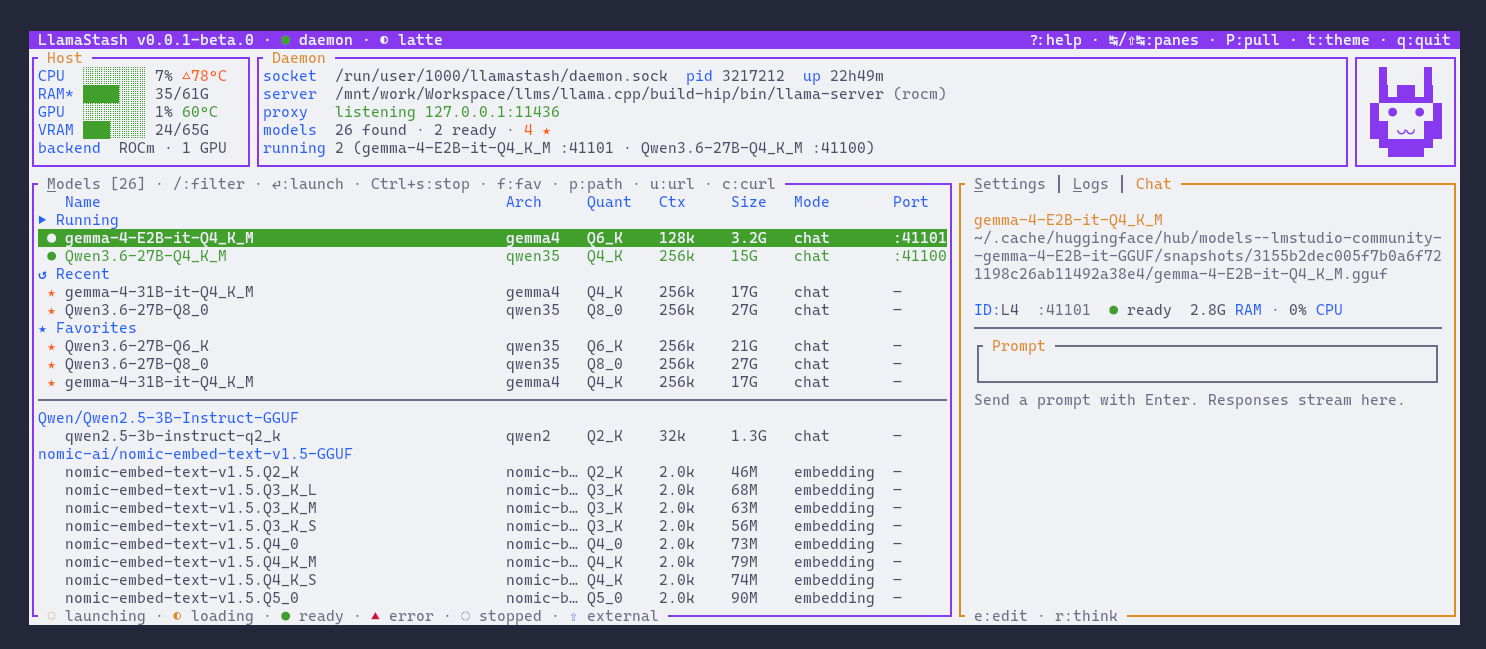
Configuration
LlamaStash reads $XDG_CONFIG_HOME/llamastash/config.yaml on Linux (fallback ~/.config/llamastash/config.yaml), ~/Library/Application Support/llamastash/config.yaml on macOS, and %APPDATA%\llamastash\config\config.yaml on Windows. A fully-annotated sample lives at config.example.yaml — copy it to the path above and edit. The full schema reference is in docs/usage.md.
Quick tour of the top-level keys:
| Key | What it controls |
|---|---|
theme | Built-in palette: macchiato (default), latte, gruvbox-dark, solarized-dark, mono. Set to custom to use the custom_theme block. Cycle live with t:theme. |
custom_theme | User-defined palette. Inherits unspecified slots from base: (default macchiato). Accepts #RRGGBB hex or ANSI names. Once defined, Custom joins the t:theme cycle. |
model_paths | Extra directories to scan for .gguf files. Merged with -p/--model-path and LLAMASTASH_MODEL_PATHS. |
disable_default_cache_paths | Per-bucket toggles (huggingface, ollama, lm_studio) for the auto-walked caches. |
disable_scan | Skip filesystem scanning entirely. Same as --no-scan / LLAMASTASH_NO_SCAN=1. |
port_range | Inclusive {start, end} TCP range the supervisor picks from. Default 41100..=41300. |
llama_server_path | Absolute path to llama-server. Overridable by --llama-server and LLAMASTASH_LLAMA_SERVER. |
probe_timeout_secs | Health-probe deadline per launch. Default 120. Bump for 70B+ on slow disks. |
keybindings | Action-name → key-spec overrides. Kdash-style dialect (ctrl+q, shift+tab, f1, …). |
Environment variables:
| Variable | Purpose |
|---|---|
LLAMASTASH_CONFIG | Override config-file path |
LLAMASTASH_LLAMA_SERVER | Path to llama-server |
LLAMASTASH_NO_SCAN | Skip filesystem scanning |
LLAMASTASH_IPC_URL | Point a CLI/TUI at a non-default daemon control plane (verbatim URL, e.g. http://127.0.0.1:48134). Must be set together with LLAMASTASH_IPC_TOKEN. |
LLAMASTASH_IPC_TOKEN | Bearer token for the control-plane URL. See LLAMASTASH_IPC_URL. |
LLAMASTASH_OFFLINE | Disable outbound network for init, pull, and doctor fetch paths. Accepts true / false when bound via clap's --offline flag; the runtime fetch::offline_requested check also accepts 1 / yes for compatibility with scripts that follow the XDG/gh convention. Equivalent to --offline. |
HF_TOKEN | HuggingFace API token. Read by init and pull only; never propagated into spawned llama-server children. Cache-file (~/.cache/huggingface/token) source is refused if its mode is group/world-readable. |
HF_ENDPOINT | Override the HuggingFace API endpoint host. Must be https:// and on the HF-allowlist (huggingface.co and its LFS CDN); non-allowlisted values are refused. Default: https://huggingface.co. |
Drive a smoke-test request against the running endpoint.
curl -s http://127.0.0.1:41100/v1/chat/completions \ -H 'Content-Type: application/json' \ -d '{"model": "qwen-coder", "messages": [{"role": "user", "content": "hi"}]}'
[First-class CLI for agents and scripts](FEATURES.md#first-class-cli-for-agents-and-scripts)
- Subcommands cover every TUI capability with
--jsonas the stable agent contract. - Documented exit codes per failure class — pin numbers, not message text.
- Colored TTY output, byte-stable TSV when piped — existing
awk/columnpipelines keep working. llamastash pull <hf-repo>— same primitive as the wizard, with disk-space prechecks.llamastash recommend— the recommender on its own, agent-friendly.- Reproducible pulls via
--revision <SHA>.
CLI exit codes
Every non-interactive subcommand returns a documented exit code so agent scripts can branch on failure class. Pin against numbers, not message text — they are the public contract.
| Code | Meaning |
|---|---|
0 | Success |
64 | Usage error (missing required arg, invalid combination — clap-emitted) |
65 | Daemon unreachable (runtime.json absent, control plane refused connection, timeout) |
66 | Model reference matched zero or multiple models (stderr lists candidates) |
67 | start_model failed at the supervisor (probe timeout, port allocation failure) |
68 | stop_model / stop_all failed |
69 | pull download failed (transport, checksum, or HF cache write) |
70 | llama-server binary not found (--llama-server, LLAMASTASH_LLAMA_SERVER, or $PATH) |
71 | Unexpected error (catch-all) |
72 | init aborted before substantive work — failed precondition, integrity check, or rate-limited GH API. Safe to re-run. |
73 | init download failed mid-step — disk space, transport, or HF cache write. Partial state recorded; re-run picks up where it stopped. |
74 | init smoke-launch failed — phase-1 dry-run exceeded VRAM ceiling, or --version probe returned non-zero. Binary is installed; re-run smoke with init --only smoke or use llamastash doctor to diagnose. |
Note on sysexits.h: the numbers above are deliberately reused from<sysexits.h>for familiarity, but LlamaStash's meanings diverge from the standard ones. Scripts that importEX_NOHOST(68) expecting "host unreachable" will get our "stop failed";EX_DATAERR(65) is reused for "daemon unreachable", not "data error". Branch on LlamaStash's table above, not the libc constants.
该项目提供快速启动LLM的功能,支持终端原生应用和CLI,代码质量较高,但缺乏更多的使用场景和文档
- 需要让 Claude / Cursor 操作本地工具的 AI 工程师
- 构建多智能体协作系统的 Agent 开发者
- 配置 MCP 服务器时建议使用 stdio 传输 + JSON-RPC,避免暴露公网
- 生产部署优先使用 Docker Compose 隔离依赖,并挂载 volume 持久化数据
- 本地部署优先选 GGUF 量化模型,节省显存并保持响应速度
- Agent 任务先做 dry-run 验证工具调用链,再开启自主执行
- API key 直接提交到 git 仓库(请用 .env 并加入 .gitignore)
- MCP 配置路径拼错或权限不足,重启 Claude Desktop 才生效
- 容器内无法访问宿主机 localhost — 使用 host.docker.internal
- 显存不足直接 OOM — 优先降低 context 或换更小的量化模型
- Docker:llamastash 提供官方镜像,docker compose up 一键启动
- CLI:直接 npm install -g / pip install,命令行调用
- 本地部署:CPU 8GB 起,GPU 推荐 16GB+ 显存
- 云端托管:可放在 Vercel / Railway / Fly.io 等 PaaS 平台
⚡ 核心功能
- 开源免费,支持本地部署,数据完全自主可控
- 活跃的 GitHub 开源社区,持续迭代更新
- 提供详细文档和使用示例,新手友好
- 支持自定义配置,灵活适配不同使用环境
- 可作为基础组件集成进现有技术栈或进行二次开发
- 需要让 Claude / Cursor 操作本地工具的 AI 工程师
- 构建多智能体协作系统的 Agent 开发者
- 配置 MCP 服务器时建议使用 stdio 传输 + JSON-RPC,避免暴露公网
- 生产部署优先使用 Docker Compose 隔离依赖,并挂载 volume 持久化数据
- 本地部署优先选 GGUF 量化模型,节省显存并保持响应速度
- Agent 任务先做 dry-run 验证工具调用链,再开启自主执行
- API key 直接提交到 git 仓库(请用 .env 并加入 .gitignore)
- MCP 配置路径拼错或权限不足,重启 Claude Desktop 才生效
- 容器内无法访问宿主机 localhost — 使用 host.docker.internal
- 显存不足直接 OOM — 优先降低 context 或换更小的量化模型
👥 适合人群
🎯 使用场景
- 本地部署运行,保护数据隐私,满足合规要求
- 自定义集成到现有系统,扩展技术栈能力
- 作为开源基础组件进行商业化二次开发
⚖️ 优点与不足
- +MIT 协议,可免费商用
- +完全开源免费,无授权费用
- +本地部署,数据完全自主可控
- +开发者社区支持,遇问题可查可问
- −安装和初始配置可能需要一定技术基础
- −功能完整性通常不如成熟商业产品
- −技术支持主要依赖开源社区,响应速度不稳定
AI Skill Hub 为第三方内容聚合平台,本页面信息基于公开数据整理,不对工具功能和质量作任何法律背书。
建议在沙箱或测试环境中充分验证后,再部署至生产环境,并做好必要的安全评估。
✅ MIT 协议 — 最宽松的开源协议之一,可自由商用、修改、分发,仅需保留版权声明。
🔗 相关工具推荐
❓ 常见问题 FAQ
总体来看,开源AI工具:快速终端原生应用(TUI)和CLI 是一款质量良好的AI工具,在同类工具中具备一定竞争力。AI Skill Hub 将持续追踪其更新动态,建议收藏备用,结合自身场景选择合适时机引入使用。
| 原始名称 | llamastash |
| 原始描述 | 开源AI工具:A fast terminal native app (TUI) and CLI with init wizard for launching local LL。⭐45 · Rust |
| Topics | installableaiggufllamacppllmlmstudiorust |
| GitHub | https://github.com/llamastash/llamastash |
| License | MIT |
| 语言 | Rust |
收录时间:2026-06-06 · 更新时间:2026-06-06 · License:MIT · AI Skill Hub 不对第三方内容的准确性作法律背书。