OptiLLM 推理优化代理
AI Skill Hub 强烈推荐:OptiLLM 推理优化代理 是一款优质的Prompt模板。已获得 4.2k 颗 GitHub Star,AI 综合评分 8.8 分,在同类工具中表现稳健。如果你正在寻找可靠的Prompt模板解决方案,这是一个值得深入了解的选择。
📚 深度解析
优质 Prompt 模板的核心价值在于其结构化设计:明确的角色设定、精确的任务描述、具体的输出格式要求和必要的边界条件,这些要素共同构成了一个能够持续产出高质量结果的 Prompt 框架。OptiLLM 推理优化代理 提供的模板经过反复迭代和用户验证,能够有效减少 AI 的"幻觉"(Hallucination)和输出不稳定问题。
无论你使用 Claude 3.5 Sonnet、GPT-4、Gemini 还是国内的文心一言、智谱 AI,优质的 Prompt 设计都能跨模型复用。AI Skill Hub 建议将本模板保存为个人 Prompt 库的标准组件,根据具体场景调整参数后反复使用,形成自己的 AI 提效工作流。
📋 工具概览
一个开源的LLM推理代理层,专注于通过Prompt优化、动态路由和缓存机制提升模型性能并降低成本。它允许用户在不修改代码的情况下优化提示词,适合需要精细化管理AI成本和响应质量的开发者及企业。
OptiLLM 推理优化代理 是经过精心设计和反复验证的专业 Prompt 模板集合。这些 Prompt 框架能够有效激活 Claude、ChatGPT 等大型语言模型的深层能力,让 AI 生成更准确、更有价值的输出结果。无需任何安装,直接复制模板内容到 AI 对话框即可使用。
📖 中文文档
一个开源的LLM推理代理层,专注于通过Prompt优化、动态路由和缓存机制提升模型性能并降低成本。它允许用户在不修改代码的情况下优化提示词,适合需要精细化管理AI成本和响应质量的开发者及企业。
OptiLLM 推理优化代理 是经过精心设计和反复验证的专业 Prompt 模板集合。这些 Prompt 框架能够有效激活 Claude、ChatGPT 等大型语言模型的深层能力,让 AI 生成更准确、更有价值的输出结果。无需任何安装,直接复制模板内容到 AI 对话框即可使用。
- 精心设计的 Prompt 框架,快速激活 AI 的深层能力
- 支持参数化替换,灵活适配多种业务场景
- 经过反复验证的指令结构,显著提升 AI 输出质量和一致性
- 适用于 Claude、ChatGPT 等主流大语言模型
- 可作为团队标准 Prompt 模板复用和二次开发
- 快速生成高质量的专业文案、分析报告或结构化内容
- 利用 Prompt 框架引导 AI 解决特定领域的复杂问题
- 在不同 AI 工具间复用经过验证的提示词模板
# Prompt 无需安装,直接复制使用 # 支持:Claude / ChatGPT / Gemini / 通义千问 等主流模型 # 使用步骤 # 1. 复制 Prompt 模板内容 # 2. 粘贴到 AI 对话框 # 3. 替换 [占位符] 为实际内容 # 4. 发送后获取结构化输出 # 获取原始文件 git clone https://github.com/algorithmicsuperintelligence/optillm
- 复制本工具的 Prompt 模板内容
- 打开 Claude、ChatGPT 或其他 AI 对话工具
- 将 Prompt 粘贴到对话框开头
- 根据实际需求替换 [占位符] 中的内容
- 发送后 AI 将按照模板格式执行,获得结构化输出
# 粘贴到 Claude/ChatGPT 使用 # 示例 Prompt 结构: 你是一位 [角色],擅长 [领域]。 请根据以下要求完成任务: 任务背景:[描述背景] 具体要求:[详细说明] 输出格式:[期望格式] # 将 [] 内内容替换为实际需求
# optillm 配置文件示例(config.yml) app: name: "optillm" debug: false log_level: "INFO" # 运行时指定配置文件 optillm --config config.yml # 或通过环境变量配置 export OPTILLM_API_KEY="your-key" export OPTILLM_OUTPUT_DIR="./output"
OptiLLM
<p align="center"> <img src="optillm-logo.png" alt="OptiLLM Logo" width="400" /> </p>
<p align="center"> <strong>🚀 2-10x accuracy improvements on reasoning tasks with zero training</strong> </p>
<p align="center"> <a href="https://github.com/algorithmicsuperintelligence/optillm/stargazers"><img src="https://img.shields.io/github/stars/algorithmicsuperintelligence/optillm?style=social" alt="GitHub stars"></a> <a href="https://pypi.org/project/optillm/"><img src="https://img.shields.io/pypi/v/optillm" alt="PyPI version"></a> <a href="https://pypi.org/project/optillm/"><img src="https://img.shields.io/pypi/dm/optillm" alt="PyPI downloads"></a> <a href="https://github.com/algorithmicsuperintelligence/optillm/blob/main/LICENSE"><img src="https://img.shields.io/github/license/algorithmicsuperintelligence/optillm" alt="License"></a> </p>
<p align="center"> <a href="https://huggingface.co/spaces/codelion/optillm">🤗 HuggingFace Space</a> • <a href="https://colab.research.google.com/drive/1SpuUb8d9xAoTh32M-9wJsB50AOH54EaH?usp=sharing">📓 Colab Demo</a> • <a href="https://github.com/algorithmicsuperintelligence/optillm/discussions">💬 Discussions</a> </p>
---
OptiLLM is an OpenAI API-compatible optimizing inference proxy that implements 20+ state-of-the-art techniques to dramatically improve LLM accuracy and performance on reasoning tasks - without requiring any model training or fine-tuning.
It is possible to beat the frontier models using these techniques across diverse tasks by doing additional compute at inference time. A good example of how to combine such techniques together is the CePO approach from Cerebras.
✨ Key Features
- 🎯 Instant Improvements: 2-10x better accuracy on math, coding, and logical reasoning
- 🔌 Drop-in Replacement: Works with any OpenAI-compatible API endpoint
- 🧠 20+ Optimization Techniques: From simple best-of-N to advanced MCTS and planning
- 📦 Zero Training Required: Just proxy your existing API calls through OptiLLM
- ⚡ Production Ready: Used in production by companies and researchers worldwide
- 🌍 Multi-Provider: Supports OpenAI, Anthropic, Google, Cerebras, and 100+ models via LiteLLM
Run all tests (requires pytest)
./tests/run_tests.sh
1. Install OptiLLM
pip install optillm
🏗️ Installation
Using docker
docker pull ghcr.io/algorithmicsuperintelligence/optillm:latest
docker run -p 8000:8000 ghcr.io/algorithmicsuperintelligence/optillm:latest
2024-10-22 07:45:05,612 - INFO - Loaded plugin: privacy
2024-10-22 07:45:06,293 - INFO - Loaded plugin: memory
2024-10-22 07:45:06,293 - INFO - Starting server with approach: autoAvailable Docker image variants:
- Full image (
latest): Includes all dependencies for local inference and plugins - Proxy-only (
latest-proxy): Lightweight image without local inference capabilities - Offline (
latest-offline): Self-contained image with pre-downloaded models (spaCy) for fully offline operation
```bash
Install from source
Clone the repository with git and use pip install to setup the dependencies.
git clone https://github.com/algorithmicsuperintelligence/optillm.git
cd optillm
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txtRunning with Docker
optillm can optionally be built and run using Docker and the provided Dockerfile.
Using Docker Compose
- Make sure you have Docker and Docker Compose installed on your system.
- Either update the environment variables in the docker-compose.yaml file or create a
.envfile in the project root directory and add any environment variables you want to set. For example, to set the OpenAI API key, add the following line to the.envfile:
OPENAI_API_KEY=your_openai_api_key_here
- Run the following command to start optillm:
docker compose up -d
This will build the Docker image if it doesn't exist and start the optillm service.
- optillm will be available at
http://localhost:8000.
When using Docker, you can set these parameters as environment variables. For example, to set the approach and model, you would use:
OPTILLM_APPROACH=mcts
OPTILLM_MODEL=gpt-4To secure the optillm proxy with an API key, set the OPTILLM_API_KEY environment variable:
OPTILLM_API_KEY=your_secret_api_keyWhen the API key is set, clients must include it in their requests using the Authorization header:
Authorization: Bearer your_secret_api_keyDevelopment Setup
```bash git clone https://github.com/algorithmicsuperintelligence/optillm.git cd optillm python -m venv .venv source .venv/bin/activate # or .venv\Scripts\activate on Windows pip install -r requirements.txt pip install -r tests/requirements.txt
🚀 Quick Start
Get powerful reasoning improvements in 3 simple steps:
```bash
Usage
Once the proxy is running, you can use it as a drop in replacement for an OpenAI client by setting the base_url as http://localhost:8000/v1.
import os
from openai import OpenAI
OPENAI_KEY = os.environ.get("OPENAI_API_KEY")
OPENAI_BASE_URL = "http://localhost:8000/v1"
client = OpenAI(api_key=OPENAI_KEY, base_url=OPENAI_BASE_URL)
response = client.chat.completions.create(
model="moa-gpt-4o",
messages=[
{
"role": "user",
"content": "Write a Python program to build an RL model to recite text from any position that the user provides, using only numpy."
}
],
temperature=0.2
)
print(response)OPENAI_API_KEY env variable with the proper key. There are multiple ways to control the optimization techniques, they are applied in the follow order of preference:
- You can control the technique you use for optimization by prepending the slug to the model name
{slug}-model-name. E.g. in the above code we are usingmoaor mixture of agents as the optimization approach. In the proxy logs you will see the following showing themoais been used with the base model asgpt-4o-mini.
2024-09-06 08:35:32,597 - INFO - Using approach moa, with gpt-4o-mini
2024-09-06 08:35:35,358 - INFO - HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-09-06 08:35:39,553 - INFO - HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-09-06 08:35:44,795 - INFO - HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-09-06 08:35:44,797 - INFO - 127.0.0.1 - - [06/Sep/2024 08:35:44] "POST /v1/chat/completions HTTP/1.1" 200 -- Or, you can pass the slug in the
optillm_approachfield in theextra_body.
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{ "role": "user","content": "" }],
temperature=0.2,
extra_body={"optillm_approach": "bon|moa|mcts"}
)system or user prompt, within <optillm_approach> </optillm_approach> tags.
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{ "role": "user","content": "<optillm_approach>re2</optillm_approach> How many r's are there in strawberry?" }],
temperature=0.2
)[!TIP] You can also combine different techniques either by using symbols&and|. When you use&the techniques are processed in the order from left to right in a pipeline with response from previous stage used as request to the next. While, with|we run all the requests in parallel and generate multiple responses that are returned as a list.
Please note that the convention described above works only when the optillm server has been started with inference approach set to auto. Otherwise, the model attribute in the client request must be set with the model name only.
We now support all LLM providers (by wrapping around the LiteLLM sdk). E.g. you can use the Gemini Flash model with moa by setting passing the api key in the environment variable os.environ['GEMINI_API_KEY'] and then calling the model moa-gemini/gemini-1.5-flash-002. In the output you will then see that LiteLLM is being used to call the base model.
9:43:21 - LiteLLM:INFO: utils.py:2952 -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
2024-09-29 19:43:21,011 - INFO -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
2024-09-29 19:43:21,481 - INFO - HTTP Request: POST https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-002:generateContent?key=[redacted] "HTTP/1.1 200 OK"
19:43:21 - LiteLLM:INFO: utils.py:988 - Wrapper: Completed Call, calling success_handler
2024-09-29 19:43:21,483 - INFO - Wrapper: Completed Call, calling success_handler
19:43:21 - LiteLLM:INFO: utils.py:2952 -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini[!TIP] optillm is a transparent proxy and will work with any LLM API or provider that has an OpenAI API compatible chat completions endpoint, and in turn, optillm also exposes the same OpenAI API compatible chat completions endpoint. This should allow you to integrate it into any existing tools or frameworks easily. If the LLM you want to use doesn't have an OpenAI API compatible endpoint (like Google or Anthropic) you can use LiteLLM proxy server that supports most LLMs.
The following sequence diagram illustrates how the request and responses go through optillm.
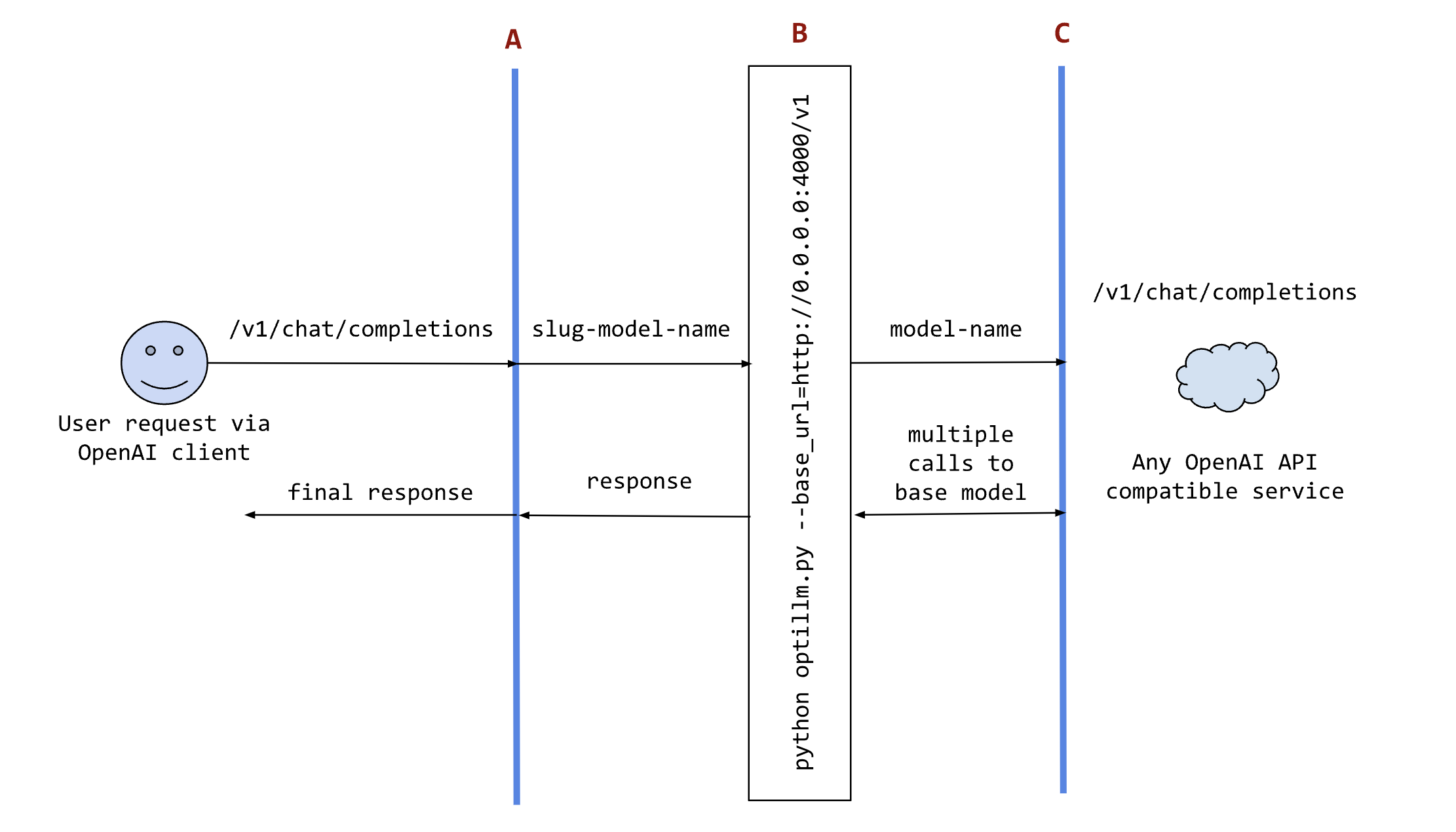
In the diagram: - A is an existing tool (like oobabooga), framework (like patchwork) or your own code where you want to use the results from optillm. You can use it directly using any OpenAI client sdk. - B is the optillm service (running directly or in a docker container) that will send requests to the base_url. - C is any service providing an OpenAI API compatible chat completions endpoint.
🔒 SSL Configuration
OptILLM supports SSL certificate verification configuration for working with self-signed certificates or corporate proxies.
Disable SSL verification (development only): ```bash
Environment variable
export OPTILLM_SSL_VERIFY=false optillm
**Use custom CA certificate:**Environment variable
export OPTILLM_SSL_CERT_PATH=/path/to/ca-bundle.crt optillm ```
⚠️ Security Note: Disabling SSL verification is insecure and should only be used in development. For production environments with custom CAs, use --ssl-cert-path instead. See SSL_CONFIGURATION.md for details.
References
- Eliciting Fine-Tuned Transformer Capabilities via Inference-Time Techniques - AutoThink: efficient inference for reasoning LLMs - Implementation - Deep Think with Confidence: Confidence-guided reasoning and inference-time scaling - Implementation - Self-Discover: Large Language Models Self-Compose Reasoning Structures - Implementation - CePO: Empowering Llama with Reasoning using Test-Time Compute - Implementation - LongCePO: Empowering LLMs to efficiently leverage infinite context - Implementation - Chain of Code: Reasoning with a Language Model-Augmented Code Emulator - Inspired the implementation of coc plugin - Entropy Based Sampling and Parallel CoT Decoding - Implementation - Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation - Evaluation script - Writing in the Margins: Better Inference Pattern for Long Context Retrieval - Inspired the implementation of the memory plugin - Chain-of-Thought Reasoning Without Prompting - Implementation - Re-Reading Improves Reasoning in Large Language Models - Implementation - In-Context Principle Learning from Mistakes - Implementation - Planning In Natural Language Improves LLM Search For Code Generation - Implementation - Self-Consistency Improves Chain of Thought Reasoning in Language Models - Implementation - Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers - Implementation - Mixture-of-Agents Enhances Large Language Model Capabilities - Inspired the implementation of moa - Prover-Verifier Games improve legibility of LLM outputs - Implementation - Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning - Inspired the implementation of mcts - Unsupervised Evaluation of Code LLMs with Round-Trip Correctness - Inspired the implementation of rto - Patched MOA: optimizing inference for diverse software development tasks - Implementation - Patched RTC: evaluating LLMs for diverse software development tasks - Implementation - AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset - Implementation - Test-Time Diffusion Deep Researcher (TTD-DR): Think More, Research More, Answer Better! - Implementation
Implemented plugins
| Plugin | Slug | Description |
|---|---|---|
| [System Prompt Learning](optillm/plugins/spl) | spl | Implements what [Andrej Karpathy called the third paradigm](https://x.com/karpathy/status/1921368644069765486) for LLM learning, this enables the model to acquire program solving knowledge and strategies |
| [Deep Think](optillm/plugins/deepthink) | deepthink | Implements a Gemini-like Deep Think approach using inference time scaling for reasoning LLMs |
| [Long-Context Cerebras Planning and Optimization](optillm/plugins/longcepo) | longcepo | Combines planning and divide-and-conquer processing of long documents to enable infinite context |
| Majority Voting | majority_voting | Generates k candidate solutions and selects the most frequent answer through majority voting (default k=6) |
| MCP Client | mcp | Implements the model context protocol (MCP) client, enabling you to use any LLM with any MCP Server |
| Router | router | Uses the [optillm-modernbert-large](https://huggingface.co/codelion/optillm-modernbert-large) model to route requests to different approaches based on the user prompt |
| Chain-of-Code | coc | Implements a chain of code approach that combines CoT with code execution and LLM based code simulation |
| Memory | memory | Implements a short term memory layer, enables you to use unbounded context length with any LLM. Set OPTILLM_MEMORY_FILE to opt in to file-backed persistence so memories survive across requests |
| Privacy | privacy | Anonymize PII data in request and deanonymize it back to original value in response |
| Read URLs | readurls | Reads all URLs found in the request, fetches the content at the URL and adds it to the context |
| Execute Code | executecode | Enables use of code interpreter to execute python code in requests and LLM generated responses |
| JSON | json | Enables structured outputs using the outlines library, supports pydantic types and JSON schema |
| GenSelect | genselect | Generative Solution Selection - generates multiple candidates and selects the best based on quality criteria |
| Web Search | web_search | Performs Google searches using Chrome automation (Selenium) to gather search results and URLs |
| [Deep Research](optillm/plugins/deep_research) | deep_research | Implements Test-Time Diffusion Deep Researcher (TTD-DR) for comprehensive research reports using iterative refinement |
| [Proxy](optillm/plugins/proxy) | proxy | Load balancing and failover across multiple LLM providers with health monitoring and round-robin routing |
We support all major LLM providers and models for inference. You need to set the correct environment variable and the proxy will pick the corresponding client.
| Provider | Required Environment Variables | Additional Notes |
|---|---|---|
| OptiLLM | OPTILLM_API_KEY | Uses the inbuilt local server for inference, supports logprobs and decoding techniques like cot_decoding & entropy_decoding |
| OpenAI | OPENAI_API_KEY | You can use this with any OpenAI compatible endpoint (e.g. OpenRouter) by setting the base_url |
| Cerebras | CEREBRAS_API_KEY | You can use this for fast inference with supported models, see [docs for details](https://inference-docs.cerebras.ai/introduction) |
| Azure OpenAI | AZURE_OPENAI_API_KEY<br>AZURE_API_VERSION<br>AZURE_API_BASE | - |
| Azure OpenAI (Managed Identity) | AZURE_API_VERSION<br>AZURE_API_BASE | Login required using az login, see [docs for details](https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/managed-identity) |
| LiteLLM | depends on the model | See [docs for details](https://docs.litellm.ai/docs/providers) |
You can then run the optillm proxy as follows.
python optillm.py
2024-09-06 07:57:14,191 - INFO - Starting server with approach: auto
2024-09-06 07:57:14,191 - INFO - Server configuration: {'approach': 'auto', 'mcts_simulations': 2, 'mcts_exploration': 0.2, 'mcts_depth': 1, 'best_of_n': 3, 'model': 'gpt-4o-mini', 'rstar_max_depth': 3, 'rstar_num_rollouts': 5, 'rstar_c': 1.4, 'base_url': '', 'host': '127.0.0.1'}
* Serving Flask app 'optillm'
* Debug mode: off
2024-09-06 07:57:14,212 - INFO - WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on http://127.0.0.1:8000
2024-09-06 07:57:14,212 - INFO - Press CTRL+C to quitSecurity Note: By default, optillm binds to127.0.0.1(localhost only) for security. To allow external connections (e.g., for Docker or remote access), use--host 0.0.0.0. Only do this on trusted networks or with proper authentication configured via--optillm-api-key.
MCP Plugin
The Model Context Protocol (MCP) plugin enables OptiLLM to connect with MCP servers, bringing external tools, resources, and prompts into the context of language models. This allows for powerful integrations with filesystem access, database queries, API connections, and more.
OptiLLM supports both local and remote MCP servers through multiple transport methods: - stdio: Local servers (traditional) - SSE: Remote servers via Server-Sent Events - WebSocket: Remote servers via WebSocket connections
What is MCP?
The Model Context Protocol (MCP) is an open protocol standard that allows LLMs to securely access tools and data sources through a standardized interface. MCP servers can provide:
- Tools: Callable functions that perform actions (like writing files, querying databases, etc.)
- Resources: Data sources for providing context (like file contents)
- Prompts: Reusable prompt templates for specific use cases
Configuration
Setting up MCP Config
Note on Backwards Compatibility: Existing MCP configurations will continue to work unchanged. The transport field defaults to "stdio" when not specified, maintaining full backwards compatibility with existing setups.
- Create a configuration file at
~/.optillm/mcp_config.jsonwith the following structure:
Local Server (stdio) - Traditional Method:
{
"mcpServers": {
"filesystem": {
"transport": "stdio",
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/path/to/allowed/directory1",
"/path/to/allowed/directory2"
],
"env": {},
"description": "Local filesystem access"
}
},
"log_level": "INFO"
}Legacy Format (still works):
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/path/to/directory"],
"env": {}
}
}
}Remote Server (SSE) - New Feature:
{
"mcpServers": {
"github": {
"transport": "sse",
"url": "https://api.githubcopilot.com/mcp",
"headers": {
"Authorization": "Bearer ${GITHUB_TOKEN}",
"Accept": "text/event-stream"
},
"timeout": 30.0,
"sse_read_timeout": 300.0,
"description": "GitHub MCP server for repository access"
}
},
"log_level": "INFO"
}Remote Server (WebSocket) - New Feature:
{
"mcpServers": {
"remote-ws": {
"transport": "websocket",
"url": "wss://api.example.com/mcp",
"description": "Remote WebSocket MCP server"
}
},
"log_level": "INFO"
}Mixed Configuration (Local + Remote):
{
"mcpServers": {
"filesystem": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/home/user/docs"],
"description": "Local filesystem access"
},
"github": {
"transport": "sse",
"url": "https://api.githubcopilot.com/mcp",
"headers": {
"Authorization": "Bearer ${GITHUB_TOKEN}"
},
"description": "GitHub MCP server"
},
"remote-api": {
"transport": "websocket",
"url": "wss://api.company.com/mcp",
"description": "Company internal MCP server"
}
},
"log_level": "INFO"
}Configuration Parameters
Common Parameters: - Server name: A unique identifier for the server (e.g., "filesystem", "github") - transport: Transport method - "stdio" (default), "sse", or "websocket" - description (optional): Description of the server's functionality - timeout (optional): Connection timeout in seconds (default: 5.0)
stdio Transport (Local Servers): - command: The executable to run the server - args: Command-line arguments for the server - env: Environment variables for the server process
sse Transport (Server-Sent Events): - url: The SSE endpoint URL - headers (optional): HTTP headers for authentication - sse_read_timeout (optional): SSE read timeout in seconds (default: 300.0)
websocket Transport (WebSocket): - url: The WebSocket endpoint URL
Environment Variable Expansion: Headers and other string values support environment variable expansion using ${VARIABLE_NAME} syntax. This is especially useful for API keys:
{
"headers": {
"Authorization": "Bearer ${GITHUB_TOKEN}",
"X-API-Key": "${MY_API_KEY}"
}
}Available MCP Servers
OptiLLM supports both local and remote MCP servers:
Local MCP Servers (stdio transport)
You can use any of the official MCP servers or third-party servers that run as local processes:
- Filesystem:
@modelcontextprotocol/server-filesystem- File operations - Git:
mcp-server-git- Git repository operations - SQLite:
@modelcontextprotocol/server-sqlite- SQLite database access - Brave Search:
@modelcontextprotocol/server-brave-search- Web search capabilities
Remote MCP Servers (SSE/WebSocket transport)
Remote servers provide centralized access without requiring local installation:
- GitHub MCP Server:
https://api.githubcopilot.com/mcp- Repository management, issue tracking, and code analysis - Third-party servers: Any MCP server that supports SSE or WebSocket protocols
Example: Comprehensive Configuration
{
"mcpServers": {
"filesystem": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/home/user/documents"],
"description": "Local file system access"
},
"search": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-brave-search"],
"env": {
"BRAVE_API_KEY": "your-api-key-here"
},
"description": "Web search capabilities"
},
"github": {
"transport": "sse",
"url": "https://api.githubcopilot.com/mcp",
"headers": {
"Authorization": "Bearer ${GITHUB_TOKEN}",
"Accept": "text/event-stream"
},
"description": "GitHub repository and issue management"
}
},
"log_level": "INFO"
}Using the MCP Plugin
Once configured, the MCP plugin will automatically:
- Connect to all configured MCP servers
- Discover available tools, resources, and prompts
- Make these capabilities available to the language model
- Handle tool calls and resource requests
The plugin enhances the system prompt with MCP capabilities so the model knows which tools are available. When the model decides to use a tool, the plugin:
- Executes the tool with the provided arguments
- Returns the results to the model
- Allows the model to incorporate the results into its response
Example Queries
Here are some examples of queries that will engage MCP tools:
Local Server Examples: - "List all the Python files in my documents directory" (Filesystem) - "What are the recent commits in my Git repository?" (Git) - "Search for the latest information about renewable energy" (Search) - "Query my database for all users who registered this month" (Database)
Remote Server Examples: - "Show me the open issues in my GitHub repository" (GitHub MCP) - "Create a new branch for the feature I'm working on" (GitHub MCP) - "What are the most recent pull requests that need review?" (GitHub MCP) - "Get the file contents from my remote repository" (GitHub MCP)
Troubleshooting
Logs
The MCP plugin logs detailed information to:
~/.optillm/logs/mcp_plugin.logCheck this log file for connection issues, tool execution errors, and other diagnostic information.
Common Issues
Local Server Issues (stdio transport):
- Command not found: Make sure the server executable is available in your PATH, or use an absolute path in the configuration.
- Access denied: For filesystem operations, ensure the paths specified in the configuration are accessible to the process.
Remote Server Issues (SSE/WebSocket transport):
- Connection timeout: Remote servers may take longer to connect. Increase the
timeoutvalue in your configuration.
- Authentication failed: Verify your API keys and tokens are correct. For GitHub MCP server, ensure your
GITHUB_TOKENenvironment variable is set with appropriate permissions.
- Network errors: Check your internet connection and verify the server URL is accessible.
- Environment variable not found: If using
${VARIABLE_NAME}syntax, ensure the environment variables are set before starting OptILLM.
General Issues:
- Method not found: Some servers don't implement all MCP capabilities (tools, resources, prompts). Verify which capabilities the server supports.
- Transport not supported: Ensure you're using a supported transport: "stdio", "sse", or "websocket".
Example: Testing GitHub MCP Connection
To test if your GitHub MCP server configuration is working:
- Set your GitHub token:
export GITHUB_TOKEN="your-github-token" - Start OptILLM and check the logs at
~/.optillm/logs/mcp_plugin.log - Look for connection success messages and discovered capabilities
Unit and Integration Tests
Additional tests are available in the tests/ directory: ```bash
Run specific test modules
pytest tests/test_plugins.py -v pytest tests/test_api_compatibility.py -v ```
AutoThink on GPQA-Diamond & MMLU-Pro (May 2025)
| **Model** | **GPQA-Diamond** | **MMLU-Pro** | ||
|---|---|---|---|---|
| Accuracy (%) | Avg. Tokens | Accuracy (%) | Avg. Tokens | |
| DeepSeek-R1-Distill-Qwen-1.5B | 21.72 | 7868.26 | 25.58 | 2842.75 |
| with Fixed Budget | 28.47 | 3570.00 | 26.18 | 1815.67 |
| **with AutoThink** | **31.06** | **3520.52** | **26.38** | **1792.50** |
aiskill88点评:将Prompt优化与推理路由解耦的优秀工具,极大地提升了LLM应用的工程化管理能力。
⚡ 核心功能
- 精心设计的 Prompt 框架,快速激活 AI 的深层能力
- 支持参数化替换,灵活适配多种业务场景
- 经过反复验证的指令结构,显著提升 AI 输出质量和一致性
- 适用于 Claude、ChatGPT 等主流大语言模型
- 可作为团队标准 Prompt 模板复用和二次开发
👥 适合人群
🎯 使用场景
- 快速生成高质量的专业文案、分析报告或结构化内容
- 利用 Prompt 框架引导 AI 解决特定领域的复杂问题
- 在不同 AI 工具间复用经过验证的提示词模板
⚖️ 优点与不足
- +Apache-2.0 协议,可免费商用
- +无需安装,立即可用
- +适配所有主流 AI 工具
- +经社区验证的最佳实践
- −效果依赖使用者对 Prompt 工程的熟悉程度
- −不同模型和版本的响应效果可能存在差异
- −复杂场景需结合实际需求二次调整
AI Skill Hub 为第三方内容聚合平台,本页面信息基于公开数据整理,不对工具功能和质量作任何法律背书。
建议在沙箱或测试环境中充分验证后,再部署至生产环境,并做好必要的安全评估。
✅ Apache 2.0 — 宽松开源协议,可商用,需保留版权声明和 NOTICE 文件,含专利授权条款。
🔗 相关工具推荐
❓ 常见问题 FAQ
总体来看,OptiLLM 推理优化代理 是一款质量优秀的Prompt模板,在同类工具中具备一定竞争力。AI Skill Hub 将持续追踪其更新动态,建议收藏备用,结合自身场景选择合适时机引入使用。
| 原始名称 | optillm |
| Topics | Prompt优化推理代理成本控制 |
| GitHub | https://github.com/algorithmicsuperintelligence/optillm |
| License | Apache-2.0 |
| 语言 | Python |
收录时间:2026-07-05 · 更新时间:2026-07-05 · License:Apache-2.0 · AI Skill Hub 不对第三方内容的准确性作法律背书。