
vLLM诊断工具
经 AI Skill Hub 精选评估,vLLM诊断工具 获评「推荐使用」。这款AI工具在功能完整性、社区活跃度和易用性方面表现出色,AI 评分 7.5 分,适合有一定技术背景的用户使用。
📚 深度解析
**为什么要使用开源工具而非商业 SaaS?**
对于个人开发者和有隐私需求的用户,本地部署的开源工具意味着数据不离本机,不受第三方服务商的数据政策约束。同时,开源工具通常没有使用次数限制和月度费用,一次安装即可长期使用,对于高频使用场景的总拥有成本(TCO)远低于订阅制商业工具。
**安装与环境准备**
vLLM诊断工具 依赖 Python 运行环境。建议通过 pyenv(Python)或 nvm(Node.js)管理 Python 版本,避免全局环境污染。对于新手用户,推荐先创建虚拟环境(python -m venv venv && source venv/bin/activate),再安装依赖,这样即使出现问题也可以随时删除虚拟环境重新开始,不影响系统稳定性。
**社区与维护**
GitHub Issue 和 Discussion 是获取帮助的最快渠道。在提问前建议先检查 Closed Issues(已关闭的问题),大多数常见问题都已有解答。遇到 Bug 时,提供 pip list 的输出、完整错误堆栈和最小可复现示例,能显著提高开发者响应速度。AI Skill Hub 将持续追踪 vLLM诊断工具 的版本更新,及时通知重要功能变化。
📋 工具概览
vLLM诊断工具 是一款基于 Python 开发的开源工具,专注于 llm、vllm、python 等核心功能。作为 GitHub 开源项目,它拥有活跃的社区支持和持续的版本迭代,代码完全透明可审计,支持本地部署以保护数据隐私。无论是个人使用还是集成到企业工作流,都能提供稳定可靠的解决方案。
📖 中文文档
vLLM诊断工具 是一款基于 Python 开发的开源工具,专注于 llm、vllm、python 等核心功能。作为 GitHub 开源项目,它拥有活跃的社区支持和持续的版本迭代,代码完全透明可审计,支持本地部署以保护数据隐私。无论是个人使用还是集成到企业工作流,都能提供稳定可靠的解决方案。
- 开源免费,支持本地部署,数据完全自主可控
- 活跃的 GitHub 开源社区,持续迭代更新
- 提供详细文档和使用示例,新手友好
- 支持自定义配置,灵活适配不同使用环境
- 可作为基础组件集成进现有技术栈或进行二次开发
- 本地部署运行,保护数据隐私,满足合规要求
- 自定义集成到现有系统,扩展技术栈能力
- 作为开源基础组件进行商业化二次开发
# 方式一:pip 安装(推荐)
pip install vllm-doctor
# 方式二:虚拟环境安装(推荐生产环境)
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install vllm-doctor
# 方式三:从源码安装(获取最新功能)
git clone https://github.com/aminalaee/vllm-doctor
cd vllm-doctor
pip install -e .
# 验证安装
python -c "import vllm_doctor; print('安装成功')"
- 访问 GitHub 仓库页面
- 按照 README 文档完成依赖安装
- 根据系统环境完成初始化配置
- 参考官方示例或文档开始使用
- 遇到问题可在 GitHub Issues 中查找解答
# 命令行使用
vllm-doctor --help
# 基本用法
vllm-doctor input_file -o output_file
# Python 代码中调用
import vllm_doctor
# 示例
result = vllm_doctor.process("input")
print(result)
# vllm-doctor 配置文件示例(config.yml) app: name: "vllm-doctor" debug: false log_level: "INFO" # 运行时指定配置文件 vllm-doctor --config config.yml # 或通过环境变量配置 export VLLM_DOCTOR_API_KEY="your-key" export VLLM_DOCTOR_OUTPUT_DIR="./output"
简介
<img src="https://raw.githubusercontent.com/aminalaee/vllm-doctor/main/docs/assets/wordmark.svg" alt="vLLM Doctor" width="360">
<p> <a href="https://pypi.org/project/vllm-doctor/"> <img src="https://badge.fury.io/py/vllm-doctor.svg" alt="Package version"> </a> <a href="https://pypi.org/project/vllm-doctor/"> <img src="https://img.shields.io/pypi/pyversions/vllm-doctor.svg?color=%2334D058" alt="Supported Python versions"> </a> </p>
Diagnose vLLM server bottlenecks from live metrics.
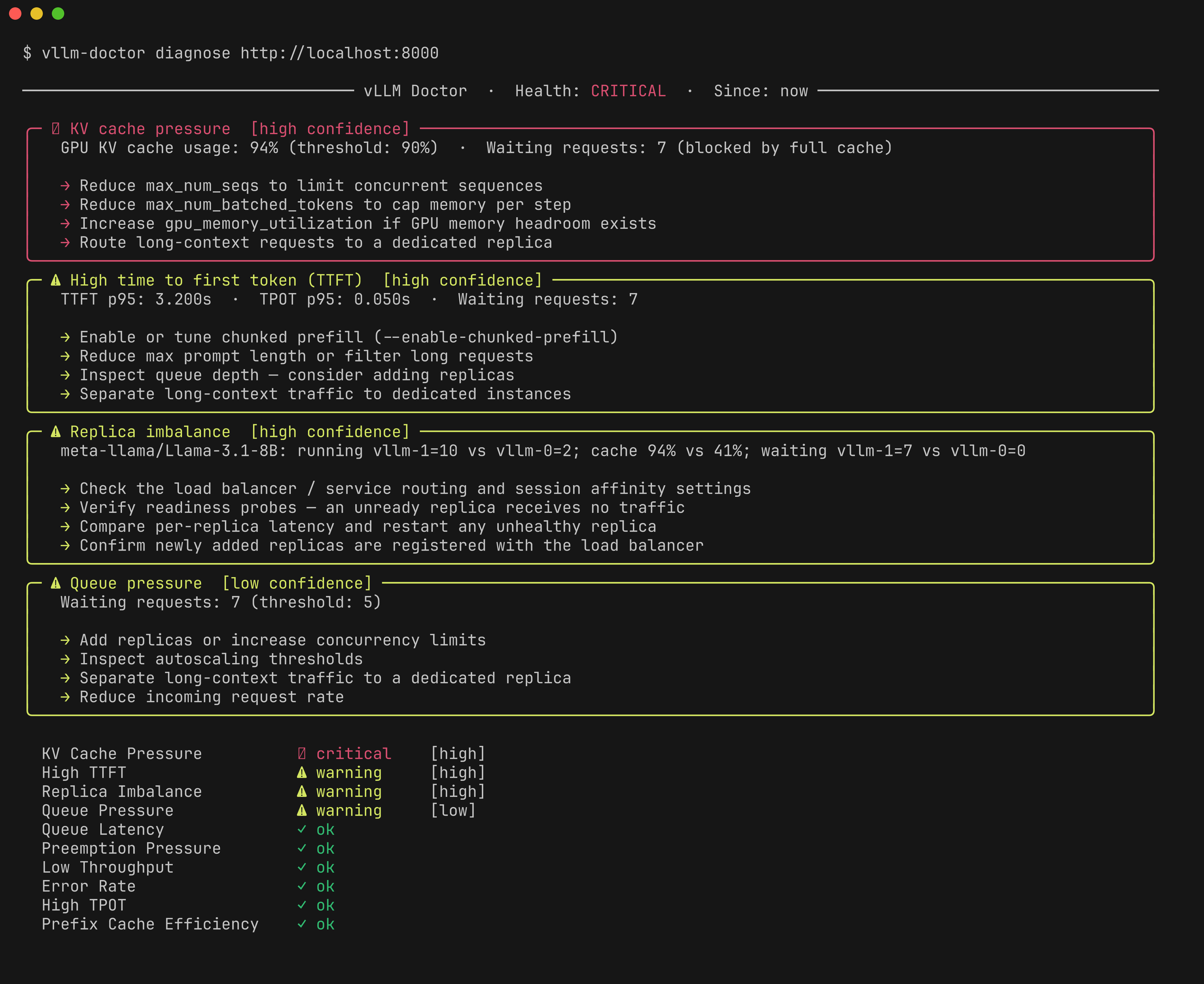
vLLM Doctor reads vLLM server metrics and turns them into diagnostic findings: what looks unhealthy, why it may be happening, and which vLLM settings are worth checking first.
vllm-doctor diagnose http://localhost:8000/metricsvLLM Doctor is not a dashboard replacement or benchmark runner. It is a fast server-side diagnostic snapshot for a single vLLM server or Prometheus target.
Installation
With pip:
pip install vllm-doctorWith uv:
uv tool install vllm-doctorRun with Docker
A prebuilt image is published to GitHub Container Registry:
docker run --rm ghcr.io/aminalaee/vllm-doctor diagnose <url><url> is your vLLM /metrics or Prometheus endpoint — the same argument the CLI takes — reachable from inside the container.
How does this relate to GuideLLM?
GuideLLM is a good fit for generating workloads and measuring endpoint behavior. vLLM Doctor is a good fit for explaining server-side symptoms from vLLM metrics.
Used together, GuideLLM can create or replay load while vLLM Doctor helps explain bottlenecks such as queue pressure, KV cache pressure, high TTFT, or high TPOT.
Quickstart
Direct scrape:
vllm-doctor diagnose http://localhost:8000/metricsPrometheus:
vllm-doctor diagnose http://localhost:9090Example verbose output
─────────────────────────────────── vLLM Doctor · Health: CRITICAL · Since: now ────────────────────────────────────
╭─ ✖ KV cache pressure [high confidence] ─────────────────────────────────────────────────────────────────────────────╮
│ GPU KV cache usage: 94% (threshold: 90%) · Waiting requests: 7 (blocked by full cache) │
│ │
│ → Reduce max_num_seqs to limit concurrent sequences │
│ → Reduce max_num_batched_tokens to cap memory per step │
│ → Increase gpu_memory_utilization if GPU memory headroom exists │
│ → Route long-context requests to a dedicated replica │
╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ ⚠ High time to first token (TTFT) [high confidence] ───────────────────────────────────────────────────────────────╮
│ TTFT p95: 3.200s · TPOT p95: 0.050s · Waiting requests: 7 │
│ │
│ → Enable or tune chunked prefill (--enable-chunked-prefill) │
│ → Reduce max prompt length or filter long requests │
│ → Inspect queue depth — consider adding replicas │
│ → Separate long-context traffic to dedicated instances │
╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ ⚠ Replica imbalance [high confidence] ─────────────────────────────────────────────────────────────────────────────╮
│ meta-llama/Llama-3.1-8B: running vllm-1=10 vs vllm-0=2; cache 94% vs 41%; waiting vllm-1=7 vs vllm-0=0 │
│ │
│ → Check the load balancer / service routing and session affinity settings │
│ → Verify readiness probes — an unready replica receives no traffic │
│ → Compare per-replica latency and restart any unhealthy replica │
│ → Confirm newly added replicas are registered with the load balancer │
╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ ⚠ Queue pressure [low confidence] ─────────────────────────────────────────────────────────────────────────────────╮
│ Waiting requests: 7 (threshold: 5) │
│ │
│ → Add replicas or increase concurrency limits │
│ → Inspect autoscaling thresholds │
│ → Separate long-context traffic to a dedicated replica │
│ → Reduce incoming request rate │
╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
KV Cache Pressure ✖ critical [high]
High TTFT ⚠ warning [high]
Replica Imbalance ⚠ warning [high]
Queue Pressure ⚠ warning [low]
Queue Latency ✓ ok
Preemption Pressure ✓ ok
Low Throughput ✓ ok
Error Rate ✓ ok
High TPOT ✓ ok
Prefix Cache Efficiency ✓ ok
─────────────────────────────────────────────────── Observed Metrics ───────────────────────────────────────────────────
Summary
Requests Running 12
Requests Waiting 7
GPU Cache Usage ███████████████████░ 94%
Prefill Tokens/s 390.0
Decode Tokens/s 252.0
Requests Success 114
Requests Error 0
Requests Aborted 0
TTFT p95 (s) 3.200
TPOT p95 (s) 0.050
Queue Time p95 (s) 0.800
Preemptions Total 0
Prefix Cache Hit Rate 50%
─────────────────────────────────────────────── Observed Metrics per pod ───────────────────────────────────────────────
vllm-1 vllm-0
Requests Running 10 2
Requests Waiting 7 0
GPU Cache Usage 94% 41%
Prefill Tokens/s 80.0 310.0
Decode Tokens/s 42.0 210.0
Requests Success 30 84
Requests Error 0 0
Requests Aborted 0 0
Preemptions Total 0 0功能齐全,易于使用,但社区支持度较低
- 需要 vllm-doctor 解决具体问题的开发者与运营人员
- 先在测试环境跑通最小用例,再接入生产数据
- API key 直接提交到 git 仓库(请用 .env 并加入 .gitignore)
- Python 依赖冲突:建议用 venv / uv 隔离环境
- 云端托管:可放在 Vercel / Railway / Fly.io 等 PaaS 平台
⚡ 核心功能
- 开源免费,支持本地部署,数据完全自主可控
- 活跃的 GitHub 开源社区,持续迭代更新
- 提供详细文档和使用示例,新手友好
- 支持自定义配置,灵活适配不同使用环境
- 可作为基础组件集成进现有技术栈或进行二次开发
- 需要 vllm-doctor 解决具体问题的开发者与运营人员
- 先在测试环境跑通最小用例,再接入生产数据
- API key 直接提交到 git 仓库(请用 .env 并加入 .gitignore)
- Python 依赖冲突:建议用 venv / uv 隔离环境
👥 适合人群
🎯 使用场景
- 本地部署运行,保护数据隐私,满足合规要求
- 自定义集成到现有系统,扩展技术栈能力
- 作为开源基础组件进行商业化二次开发
⚖️ 优点与不足
- +完全开源免费,无授权费用
- +本地部署,数据完全自主可控
- +开发者社区支持,遇问题可查可问
- −未明确开源协议,商用场景需谨慎评估
- −安装和初始配置可能需要一定技术基础
- −功能完整性通常不如成熟商业产品
- −技术支持主要依赖开源社区,响应速度不稳定
该工具未明确声明开源协议,商业使用前请联系原作者确认授权范围,避免侵权风险。
AI Skill Hub 为第三方内容聚合平台,本页面信息基于公开数据整理,不对工具功能和质量作任何法律背书。
建议在沙箱或测试环境中充分验证后,再部署至生产环境,并做好必要的安全评估。
🔗 相关工具推荐
❓ 常见问题 FAQ
AI Skill Hub 点评:vLLM诊断工具 的核心功能完整,质量良好。对于AI 技术爱好者来说,这是一个值得纳入个人工具库的选择。建议先在非生产环境试用,再逐步推广。
| 原始名称 | vllm-doctor |
| 原始描述 | 开源AI工具:Diagnostic tool for vLLM inference servers。⭐11 · Python |
| Topics | llmvllmpython |
| GitHub | https://github.com/aminalaee/vllm-doctor |
| 语言 | Python |
收录时间:2026-06-11 · 更新时间:2026-06-11 · License:未公布 · AI Skill Hub 不对第三方内容的准确性作法律背书。