
memsearch Agent工作流
AI Skill Hub 强烈推荐:memsearch Agent工作流 是一款优质的AI工具。已获得 1.7k 颗 GitHub Star,AI 综合评分 8.2 分,在同类工具中表现稳健。如果你正在寻找可靠的AI工具解决方案,这是一个值得深入了解的选择。
📚 深度解析
**为什么要使用开源工具而非商业 SaaS?**
对于个人开发者和有隐私需求的用户,本地部署的开源工具意味着数据不离本机,不受第三方服务商的数据政策约束。同时,开源工具通常没有使用次数限制和月度费用,一次安装即可长期使用,对于高频使用场景的总拥有成本(TCO)远低于订阅制商业工具。
**安装与环境准备**
memsearch Agent工作流 依赖 Python 运行环境。建议通过 pyenv(Python)或 nvm(Node.js)管理 Python 版本,避免全局环境污染。对于新手用户,推荐先创建虚拟环境(python -m venv venv && source venv/bin/activate),再安装依赖,这样即使出现问题也可以随时删除虚拟环境重新开始,不影响系统稳定性。
**社区与维护**
GitHub Issue 和 Discussion 是获取帮助的最快渠道。在提问前建议先检查 Closed Issues(已关闭的问题),大多数常见问题都已有解答。遇到 Bug 时,提供 pip list 的输出、完整错误堆栈和最小可复现示例,能显著提高开发者响应速度。AI Skill Hub 将持续追踪 memsearch Agent工作流 的版本更新,及时通知重要功能变化。
📋 工具概览
为Claude、GPT等AI智能体提供统一的持久化记忆存储方案。支持多代理协作,实现跨会话的知识积累和上下文保留。适合构建长期运行的AI工作流和多轮交互应用开发者。
memsearch Agent工作流 是一款基于 Python 开发的开源工具,专注于 智能体内存、AI工作流、多代理协作 等核心功能。作为 GitHub 开源项目,它拥有活跃的社区支持和持续的版本迭代,代码完全透明可审计,支持本地部署以保护数据隐私。无论是个人使用还是集成到企业工作流,都能提供稳定可靠的解决方案。
📖 中文文档
为Claude、GPT等AI智能体提供统一的持久化记忆存储方案。支持多代理协作,实现跨会话的知识积累和上下文保留。适合构建长期运行的AI工作流和多轮交互应用开发者。
memsearch Agent工作流 是一款基于 Python 开发的开源工具,专注于 智能体内存、AI工作流、多代理协作 等核心功能。作为 GitHub 开源项目,它拥有活跃的社区支持和持续的版本迭代,代码完全透明可审计,支持本地部署以保护数据隐私。无论是个人使用还是集成到企业工作流,都能提供稳定可靠的解决方案。
- 开源免费,支持本地部署,数据完全自主可控
- 活跃的 GitHub 开源社区,持续迭代更新
- 提供详细文档和使用示例,新手友好
- 支持自定义配置,灵活适配不同使用环境
- 可作为基础组件集成进现有技术栈或进行二次开发
- 本地部署运行,保护数据隐私,满足合规要求
- 自定义集成到现有系统,扩展技术栈能力
- 作为开源基础组件进行商业化二次开发
# 方式一:pip 安装(推荐)
pip install memsearch
# 方式二:虚拟环境安装(推荐生产环境)
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install memsearch
# 方式三:从源码安装(获取最新功能)
git clone https://github.com/zilliztech/memsearch
cd memsearch
pip install -e .
# 验证安装
python -c "import memsearch; print('安装成功')"
- 访问 GitHub 仓库页面
- 按照 README 文档完成依赖安装
- 根据系统环境完成初始化配置
- 参考官方示例或文档开始使用
- 遇到问题可在 GitHub Issues 中查找解答
# 命令行使用
memsearch --help
# 基本用法
memsearch input_file -o output_file
# Python 代码中调用
import memsearch
# 示例
result = memsearch.process("input")
print(result)
# memsearch 配置文件示例(config.yml) app: name: "memsearch" debug: false log_level: "INFO" # 运行时指定配置文件 memsearch --config config.yml # 或通过环境变量配置 export MEMSEARCH_API_KEY="your-key" export MEMSEARCH_OUTPUT_DIR="./output"
简介
 memsearch
memsearch
<p align="center"> <strong>Cross-platform semantic memory for AI coding agents.</strong> </p>
<p align="center"> <a href="https://pypi.org/project/memsearch/"><img src="https://img.shields.io/pypi/v/memsearch?style=flat-square&color=blue" alt="PyPI"></a> <a href="https://zilliztech.github.io/memsearch/platforms/claude-code/"><img src="https://img.shields.io/badge/Claude_Code-plugin-c97539?style=flat-square&logo=claude&logoColor=white" alt="Claude Code"></a> <a href="https://zilliztech.github.io/memsearch/platforms/openclaw/"><img src="https://img.shields.io/badge/OpenClaw-plugin-4a9eff?style=flat-square" alt="OpenClaw"></a> <a href="https://zilliztech.github.io/memsearch/platforms/opencode/"><img src="https://img.shields.io/badge/OpenCode-plugin-22c55e?style=flat-square" alt="OpenCode"></a> <a href="https://zilliztech.github.io/memsearch/platforms/codex/"><img src="https://img.shields.io/badge/Codex_CLI-plugin-ff6b35?style=flat-square" alt="Codex CLI"></a> <a href="https://pypi.org/project/memsearch/"><img src="https://img.shields.io/badge/python-%3E%3D3.10-blue?style=flat-square&logo=python&logoColor=white" alt="Python"></a> <a href="https://github.com/zilliztech/memsearch/blob/main/LICENSE"><img src="https://img.shields.io/github/license/zilliztech/memsearch?style=flat-square" alt="License"></a> <a href="https://github.com/zilliztech/memsearch/actions/workflows/test.yml"><img src="https://img.shields.io/github/actions/workflow/status/zilliztech/memsearch/test.yml?branch=main&style=flat-square" alt="Tests"></a> <a href="https://zilliztech.github.io/memsearch/"><img src="https://img.shields.io/badge/docs-memsearch-blue?style=flat-square" alt="Docs"></a> <a href="https://github.com/zilliztech/memsearch/stargazers"><img src="https://img.shields.io/github/stars/zilliztech/memsearch?style=flat-square" alt="Stars"></a> <a href="https://discord.com/invite/FG6hMJStWu"><img src="https://img.shields.io/badge/Discord-chat-7289da?style=flat-square&logo=discord&logoColor=white" alt="Discord"></a> <a href="https://x.com/zilliz_universe"><img src="https://img.shields.io/badge/follow-%40zilliz__universe-000000?style=flat-square&logo=x&logoColor=white" alt="X (Twitter)"></a> </p>
<p align="center"> <img src="https://github.com/user-attachments/assets/427b7152-bc16-408c-a8b0-59a2b05fd1e0" alt="memsearch demo" width="800"> </p>
🏗️ Architecture Overview
┌──────────────────────────────────────────────────────────────┐
│ 🧑💻 For Agent Users (Plugins) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌────────┐ ┌──────┐ │
│ │ Claude │ │ OpenClaw │ │ OpenCode │ │ Codex │ │ Your │ │
│ │ Code │ │ Plugin │ │ Plugin │ │ Plugin │ │ App │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ └───┬────┘ └──┬───┘ │
│ └─────────────┴────────────┴───────────┴────────┘ │
├────────────────────────────┬─────────────────────────────────┤
│ 🛠️ For Agent Developers │ Build your own with ↓ │
│ ┌─────────────────────────┴──────────────────────────────┐ │
│ │ memsearch CLI / Python API │ │
│ │ index · search · expand · watch · compact │ │
│ └─────────────────────────┬──────────────────────────────┘ │
│ ┌─────────────────────────┴──────────────────────────────┐ │
│ │ Core: Chunker → Embedder → Milvus │ │
│ │ Hybrid Search (BM25 + Dense + RRF) │ │
│ └────────────────────────────────────────────────────────┘ │
├──────────────────────────────────────────────────────────────┤
│ 📄 Markdown Files (Source of Truth) │
│ memory/2026-03-27.md · memory/2026-03-26.md · ... │
└──────────────────────────────────────────────────────────────┘Plugins sit on top of the CLI/API layer. The API handles indexing, searching, and Milvus sync. Markdown files are always the source of truth — Milvus is a rebuildable shadow index. Everything below the plugin layer is what you use as an agent developer.
📰 What's New
- Skills from memory — MemSearch now distills the workflows you repeat into reusable, installable agent skills (a third "procedural memory" layer) and keeps them up to date in the background. See Skills from Memory.
- Advanced memory maintenance — optional background tasks keep durable
PROJECT.mdandUSER.mdnotes current across sessions. See Advanced Memory Maintenance.
---
Install as a project dependency — use this if you want to import
As a project dependency
uv add "memsearch[onnx]"
Install
/plugin marketplace add zilliztech/memsearch /plugin install memsearch
Install
git clone --depth 1 https://github.com/zilliztech/memsearch.git bash memsearch/plugins/codex/scripts/install.sh codex --yolo # needed for ONNX model network access
After installing, chat as usual. Hooks capture and summarize each turn.
**Verify it's working:**
**Recall memories** — use the skill:
> 📖 [Codex CLI Plugin docs](https://zilliztech.github.io/memsearch/platforms/codex/)
</details>
<details>
<summary><h3>For OpenClaw Users</h3></summary>
Install from ClawHub
openclaw plugins install --force clawhub:memsearch openclaw config set plugins.entries.memsearch.hooks.allowConversationAccess true openclaw config set plugins.entries.memsearch.hooks.allowPromptInjection true openclaw gateway restart
After installing, chat in TUI as usual. The plugin captures each turn automatically.
**Verify it's working** — memory files are stored in your agent's workspace:
Works out of the box, no setup needed
memsearch config get milvus.uri # → ~/.memsearch/milvus.db
⭐ **Zilliz Cloud** (recommended) — fully managed, [free tier available](https://cloud.zilliz.com/signup?utm_source=github&utm_medium=referral&utm_campaign=memsearch-readme) — [sign up](https://cloud.zilliz.com/signup?utm_source=github&utm_medium=referral&utm_campaign=memsearch-readme) 👇:
<details>
<summary>⭐ Sign up for a free Zilliz Cloud cluster</summary>
You can [sign up](https://cloud.zilliz.com/signup?utm_source=github&utm_medium=referral&utm_campaign=memsearch-readme) on Zilliz Cloud to get a free cluster and API key.
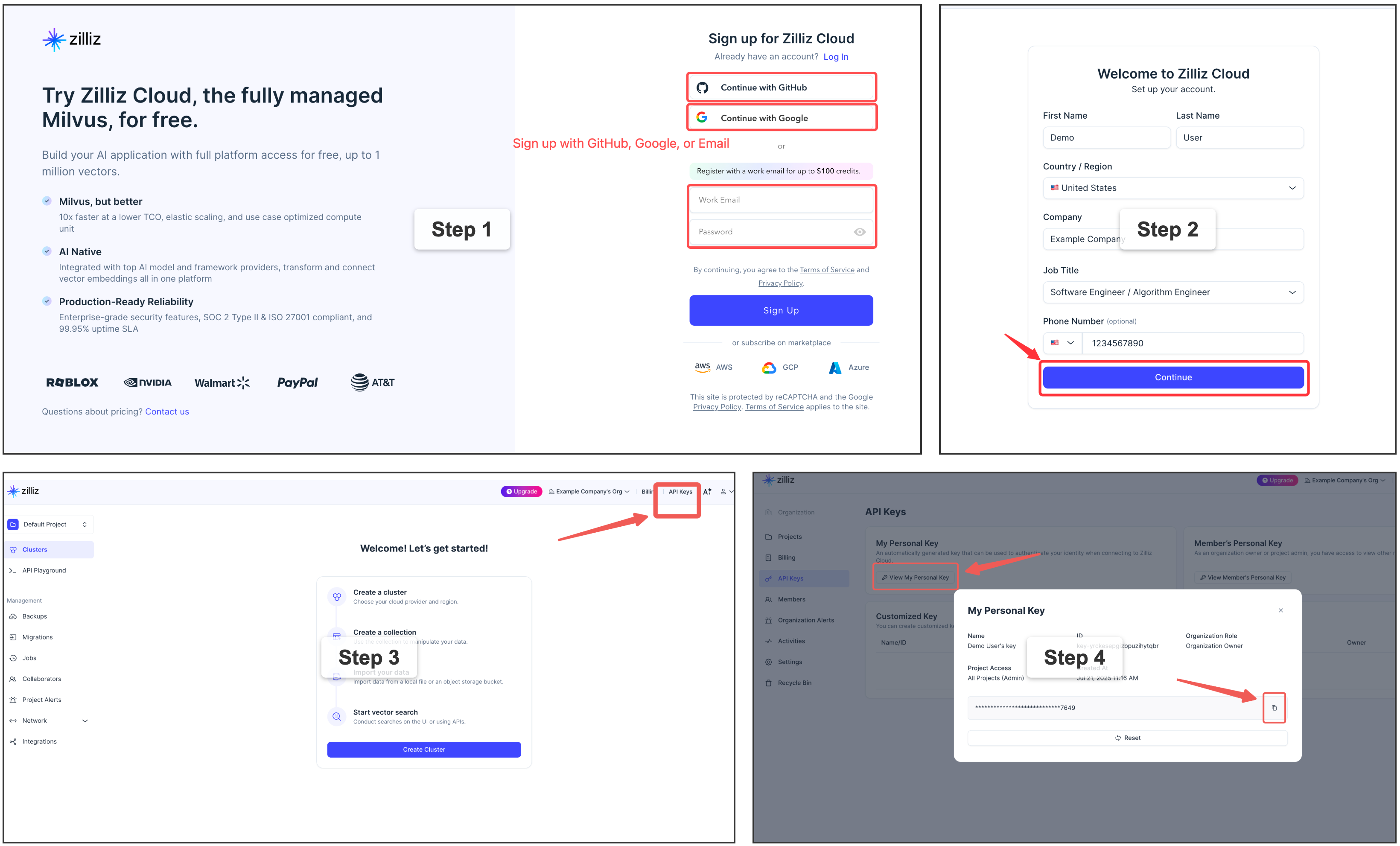
</details>
<details>
<summary>Self-hosted Milvus Server (Docker) — for advanced users</summary>
For multi-user or team environments with a dedicated Milvus instance. Requires Docker. See the [official installation guide](https://milvus.io/docs/install_standalone-docker-compose.md).
</details>
> 📖 Full configuration guide: [Configuration](https://zilliztech.github.io/memsearch/home/configuration/) · [Platform comparison](https://zilliztech.github.io/memsearch/platforms/)
#### Capture Summarization Routing
Each plugin keeps its native capture summarizer unless you override it explicitly:
Advanced users can route plugin summarization through a memsearch-managed API provider:
Leave `plugins.<platform>.summarize.provider` empty or set it to `native` to preserve the default behavior. Plugin-specific summarize settings do not fall back to `llm.model`.
You can also disable automatic capture for a project while keeping the plugin installed:
Advanced Memory Maintenance
Your agent can keep two higher-level notes current in the background: PROJECT.md — durable project state (active threads, decisions, risks, next steps) — and USER.md — your reusable preferences, working style, and recurring goals. They refresh after a session only when the journals changed and a minimum interval has passed, and they are off by default.
Turn them on by asking your agent — "enable MemSearch's PROJECT.md and USER.md maintenance" — and it configures them through the memory-config skill, which can also choose the model/provider, the interval, and custom prompts, or diagnose the current setup. Prefer editing files? The settings live under [plugins.<agent>.project_review] and [plugins.<agent>.user_profile] in your MemSearch config (both read .memsearch/memory and write .memsearch/PROJECT.md / .memsearch/USER.md by default).
If a background maintenance task seems silent, check .memsearch/.maintenance-state.json or ask the memory-config skill to inspect it; failed runs record last_error and retry on the next due run because failed input digests are not marked successful.
Skills from Memory
Beyond the episodic journals and the semantic PROJECT.md / USER.md notes, MemSearch grows a third memory layer — procedural memory: your agent turns the workflows you repeat into reusable, installable skills. You drive it entirely through your agent, in natural language — nothing to memorize:
- "Make a skill out of what we just did." — the agent drafts a skill from the session (reading the original transcript so the steps are exact, not guessed), saves it as a candidate, and offers to install it.
- "What skill candidates do I have? Install the deploy one." — the agent lists candidates and installs the one you pick into its own skill directory, where it becomes a real
/-command.
<p align="center"> <img width="1086" height="752" alt="MemSearch skill distillation demo" src="https://github.com/user-attachments/assets/39a90f1c-54e3-4c7a-b168-051f0e096d39"> </p>
Under the hood, candidates live in a git-tracked .memsearch/skill-candidates/ store — diffable and revertible, and inert until you install one (that step is always yours). An optional background pass can also mine recurring workflows from your history on its own. Distilled skills follow the Agent Skills open standard, so one capture is portable across Claude Code, Codex, OpenCode, and others.
Turning it on is also just a sentence: ask your agent "enable MemSearch skill distillation" (or "make it more eager") and it configures things through the memory-config skill — it's off by default. Prefer editing files? The same settings live under [plugins.<agent>.memory_to_skill] in your MemSearch config. Full guide: Skills from Memory.
📦 Installation
```bash
Install as a global CLI tool — recommended when you mainly use the
How Plugins Work (Claude Code as example)
Capture — after each conversation turn:
User asks question → Agent responds → Stop hook fires
│
┌────────────────────┘
▼
Parse last turn
│
▼
LLM summarizes (haiku)
"- User asked about X."
"- Claude did Y."
│
▼
Append to memory/2026-03-27.md
with anchor
│
▼
memsearch index → MilvusRecall — 3-layer progressive search:
User: "What did we discuss about batch size?"
│
▼
L1 memsearch search "batch size" → ranked chunks
│ (need more?)
▼
L2 memsearch expand <chunk_hash> → full .md section
│ (need original?)
▼
L3 parse-transcript <session.jsonl> → raw dialogue⌨️ CLI Usage
Setup:
memsearch config init # interactive setup wizard
memsearch config set embedding.provider onnx # switch embedding provider
memsearch config set milvus.uri http://localhost:19530 # switch Milvus backendIndex & Search:
memsearch index ./memory/ # index markdown files
memsearch index ./memory/ ./notes/ --force # re-embed everything
memsearch search "Redis caching" # hybrid search (BM25 + vector)
memsearch search "auth flow" --top-k 10 --json-output # JSON for scripting
memsearch expand <chunk_hash> # show full section around a chunkLive Sync & Maintenance:
memsearch watch ./memory/ # live file watcher (auto-index on change)
memsearch compact # LLM-powered chunk summarization
memsearch stats # show indexed chunk count
memsearch reset --yes # drop all indexed data and rebuild📖 Full CLI reference with all flags: CLI docs
⚙️ Configuration (all platforms)
All plugins share the same memsearch backend. Configure once, works everywhere.
Embedding
Defaults to ONNX bge-m3 — runs locally on CPU, no API key, no cost. On first launch the model (~558 MB) is downloaded from HuggingFace Hub.
memsearch config set embedding.provider onnx # default — local, free
memsearch config set embedding.provider openai # needs OPENAI_API_KEY
memsearch config set embedding.provider ollama # local, any modelAll providers and models: Configuration — Embedding Provider
Milvus Backend
Just change milvus_uri (and optionally milvus_token) to switch between deployment modes:
Milvus Lite (default) — zero config, single file. Great for getting started:
```bash
Other options: [openai], [google], [voyage], [jina], [mistral], [ollama], [local], [all]
```
</details>
⚙️ Configuration
Embedding and Milvus backend settings → Configuration (all platforms)
Settings priority: Built-in defaults → ~/.memsearch/config.toml → .memsearch.toml → CLI flags.
📖 Full config guide: Configuration
As a CLI tool (recommended — local ONNX, no API key)
uv tool install "memsearch[onnx]" pipx install "memsearch[onnx]" pip install "memsearch[onnx]"
🐍 Python API — Give Your Agent Memory
from memsearch import MemSearch
mem = MemSearch(paths=["./memory"])
await mem.index() # index markdown files
results = await mem.search("Redis config", top_k=3) # semantic search
scoped = await mem.search("pricing", top_k=3, source_prefix="./memory/product")
print(results[0]["content"], results[0]["score"]) # content + similarity<details> <summary><b>Full example — agent with memory (OpenAI)</b> — click to expand</summary>
import asyncio
from datetime import date
from pathlib import Path
from openai import OpenAI
from memsearch import MemSearch
MEMORY_DIR = "./memory"
llm = OpenAI() # your LLM client
mem = MemSearch(paths=[MEMORY_DIR]) # memsearch handles the rest
def save_memory(content: str):
"""Append a note to today's memory log (OpenClaw-style daily markdown)."""
p = Path(MEMORY_DIR) / f"{date.today()}.md"
p.parent.mkdir(parents=True, exist_ok=True)
with open(p, "a") as f:
f.write(f"\n{content}\n")
async def agent_chat(user_input: str) -> str:
# 1. Recall — search past memories for relevant context
memories = await mem.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. Think — call LLM with memory context
resp = llm.chat.completions.create(
model="gpt-5-mini",
messages=[
{"role": "system", "content": f"You have these memories:\n{context}"},
{"role": "user", "content": user_input},
],
)
answer = resp.choices[0].message.content
# 3. Remember — save this exchange and index it
save_memory(f"## {user_input}\n{answer}")
await mem.index()
return answer
async def main():
# Seed some knowledge
save_memory("## Team\n- Alice: frontend lead\n- Bob: backend lead")
save_memory("## Decision\nWe chose Redis for caching over Memcached.")
await mem.index() # or mem.watch() to auto-index in the background
# Agent can now recall those memories
print(await agent_chat("Who is our frontend lead?"))
print(await agent_chat("What caching solution did we pick?"))
asyncio.run(main())</details>
<details> <summary><b>Anthropic Claude example</b> — click to expand</summary>
pip install memsearch anthropicimport asyncio
from datetime import date
from pathlib import Path
from anthropic import Anthropic
from memsearch import MemSearch
MEMORY_DIR = "./memory"
llm = Anthropic()
mem = MemSearch(paths=[MEMORY_DIR])
def save_memory(content: str):
p = Path(MEMORY_DIR) / f"{date.today()}.md"
p.parent.mkdir(parents=True, exist_ok=True)
with open(p, "a") as f:
f.write(f"\n{content}\n")
async def agent_chat(user_input: str) -> str:
# 1. Recall
memories = await mem.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. Think — call Claude with memory context
resp = llm.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=f"You have these memories:\n{context}",
messages=[{"role": "user", "content": user_input}],
)
answer = resp.content[0].text
# 3. Remember
save_memory(f"## {user_input}\n{answer}")
await mem.index()
return answer
async def main():
save_memory("## Team\n- Alice: frontend lead\n- Bob: backend lead")
await mem.index()
print(await agent_chat("Who is our frontend lead?"))
asyncio.run(main())</details>
<details> <summary><b>Ollama (fully local, no API key)</b> — click to expand</summary>
pip install "memsearch[ollama]"
ollama pull nomic-embed-text # embedding model
ollama pull llama3.2 # chat modelimport asyncio
from datetime import date
from pathlib import Path
from ollama import chat
from memsearch import MemSearch
MEMORY_DIR = "./memory"
mem = MemSearch(paths=[MEMORY_DIR], embedding_provider="ollama")
def save_memory(content: str):
p = Path(MEMORY_DIR) / f"{date.today()}.md"
p.parent.mkdir(parents=True, exist_ok=True)
with open(p, "a") as f:
f.write(f"\n{content}\n")
async def agent_chat(user_input: str) -> str:
# 1. Recall
memories = await mem.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. Think — call Ollama locally
resp = chat(
model="llama3.2",
messages=[
{"role": "system", "content": f"You have these memories:\n{context}"},
{"role": "user", "content": user_input},
],
)
answer = resp.message.content
# 3. Remember
save_memory(f"## {user_input}\n{answer}")
await mem.index()
return answer
async def main():
save_memory("## Team\n- Alice: frontend lead\n- Bob: backend lead")
await mem.index()
print(await agent_chat("Who is our frontend lead?"))
asyncio.run(main())</details>
📖 Full Python API reference: Python API docs
Restart Claude Code to activate the plugin
After restarting, just chat with Claude Code as usual. The plugin captures every conversation turn automatically.
**Verify it's working** — after a few conversations, check your memory files:
**Recall memories** — two ways to trigger:
Or just ask naturally — Claude auto-invokes the skill when it senses the question needs history:
> 📖 [Claude Code Plugin docs](https://zilliztech.github.io/memsearch/platforms/claude-code/) · [Troubleshooting](https://zilliztech.github.io/memsearch/platforms/claude-code/troubleshooting/)
</details>
<details open>
<summary><h3>For Codex CLI Users</h3></summary>
`memsearch` command or any of the agent plugins (Claude Code, Codex,
memsearch 是一个专为 AI coding agents 设计的跨平台语义记忆库。它能够为 Claude Code、OpenClaw、OpenCode 等各类 AI 智能体提供持久化的上下文记忆能力,让 AI 能够像人类一样“记住”之前的对话内容,从而实现更智能、更具连续性的开发协作体验。
若需将 memsearch 作为项目依赖项集成,请使用 uv 工具进行安装,并确保包含 [onnx] 扩展以支持本地化运行。
支持多种安装方式:可通过插件市场直接添加(如 /plugin marketplace add);也可通过 git clone 源码并运行安装脚本进行部署。对于 OpenClaw 用户,可以通过 CLI 命令强制安装并配置权限。安装完成后,系统会自动处理 ONNX 模型等必要组件。
memsearch 采用“捕获-索引-检索”的工作流。在对话过程中,插件会自动捕获并使用 LLM(如 Haiku)对对话进行摘要,随后将内容持久化存储。当用户发起相关查询时,系统会通过三层渐进式搜索机制,在 Milvus 向量数据库中检索相关记忆,实现精准的语义召回。
所有平台插件共享统一的 memsearch 后端配置。默认使用 ONNX bge-m3 模型进行本地 Embedding 计算,无需 API Key 且零成本。配置优先级遵循:内置默认值 < ~/.memsearch/config.toml < .memsearch.toml < CLI 参数。支持通过 CLI 灵活切换 Embedding provider(如 OpenAI, Google, Jina 等)及 Milvus 后端地址。
除了 CLI 工具外,开发者还可以通过 Python API 为自己的 Agent 赋予记忆能力。通过导入 memsearch 模块,可以轻松实现对本地 Markdown 文件的索引(index)以及基于语义的搜索(search),并支持通过 source_prefix 进行作用域限定,实现精准的知识检索。
安装完成后,重启 Claude Code 等 Agent 即可激活插件。插件会在后台自动捕获每一轮对话,并将摘要存入 .memsearch/memory/ 目录下的每日 .md 文件中。用户可以通过 memsearch CLI 或 Agent 内置的 skill(如 $memory-recall)直接调用记忆,实现自然语言驱动的上下文检索。
创新的AI代理记忆解决方案,解决长期交互的核心痛点。架构清晰,社区活跃度好,实用性强。
- 构建多智能体协作系统的 Agent 开发者
- 构建企业知识库 / RAG 检索应用的团队
- 生产部署优先使用 Docker Compose 隔离依赖,并挂载 volume 持久化数据
- 本地部署优先选 GGUF 量化模型,节省显存并保持响应速度
- 分块大小建议 256-512 tokens,向量库优选 pgvector 或 Qdrant
- Agent 任务先做 dry-run 验证工具调用链,再开启自主执行
- API key 直接提交到 git 仓库(请用 .env 并加入 .gitignore)
- 容器内无法访问宿主机 localhost — 使用 host.docker.internal
- embedding 模型与查询模型不一致导致检索失效
- 显存不足直接 OOM — 优先降低 context 或换更小的量化模型
- Python 依赖冲突:建议用 venv / uv 隔离环境
- Docker:memsearch 提供官方镜像,docker compose up 一键启动
- CLI:直接 npm install -g / pip install,命令行调用
- 本地部署:CPU 8GB 起,GPU 推荐 16GB+ 显存
- 云端托管:可放在 Vercel / Railway / Fly.io 等 PaaS 平台
⚡ 核心功能
- 开源免费,支持本地部署,数据完全自主可控
- 活跃的 GitHub 开源社区,持续迭代更新
- 提供详细文档和使用示例,新手友好
- 支持自定义配置,灵活适配不同使用环境
- 可作为基础组件集成进现有技术栈或进行二次开发
- 构建多智能体协作系统的 Agent 开发者
- 构建企业知识库 / RAG 检索应用的团队
- 生产部署优先使用 Docker Compose 隔离依赖,并挂载 volume 持久化数据
- 本地部署优先选 GGUF 量化模型,节省显存并保持响应速度
- 分块大小建议 256-512 tokens,向量库优选 pgvector 或 Qdrant
- Agent 任务先做 dry-run 验证工具调用链,再开启自主执行
- API key 直接提交到 git 仓库(请用 .env 并加入 .gitignore)
- 容器内无法访问宿主机 localhost — 使用 host.docker.internal
- embedding 模型与查询模型不一致导致检索失效
- 显存不足直接 OOM — 优先降低 context 或换更小的量化模型
👥 适合人群
🎯 使用场景
- 本地部署运行,保护数据隐私,满足合规要求
- 自定义集成到现有系统,扩展技术栈能力
- 作为开源基础组件进行商业化二次开发
⚖️ 优点与不足
- +MIT 协议,可免费商用
- +完全开源免费,无授权费用
- +本地部署,数据完全自主可控
- +开发者社区支持,遇问题可查可问
- −安装和初始配置可能需要一定技术基础
- −功能完整性通常不如成熟商业产品
- −技术支持主要依赖开源社区,响应速度不稳定
AI Skill Hub 为第三方内容聚合平台,本页面信息基于公开数据整理,不对工具功能和质量作任何法律背书。
建议在沙箱或测试环境中充分验证后,再部署至生产环境,并做好必要的安全评估。
✅ MIT 协议 — 最宽松的开源协议之一,可自由商用、修改、分发,仅需保留版权声明。
🔗 相关工具推荐
❓ 常见问题 FAQ
总体来看,memsearch Agent工作流 是一款质量优秀的AI工具,在同类工具中具备一定竞争力。AI Skill Hub 将持续追踪其更新动态,建议收藏备用,结合自身场景选择合适时机引入使用。
| 原始名称 | memsearch |
| 原始描述 | 开源AI工作流:A persistent, unified memory layer for all your AI agents (e.g. Claude Code, Cod。⭐1.7k · Python |
| Topics | 智能体内存AI工作流多代理协作持久化存储Claude集成 |
| GitHub | https://github.com/zilliztech/memsearch |
| License | MIT |
| 语言 | Python |
收录时间:2026-05-18 · 更新时间:2026-05-19 · License:MIT · AI Skill Hub 不对第三方内容的准确性作法律背书。